


Scalable System Design Patterns

System Design Refresher
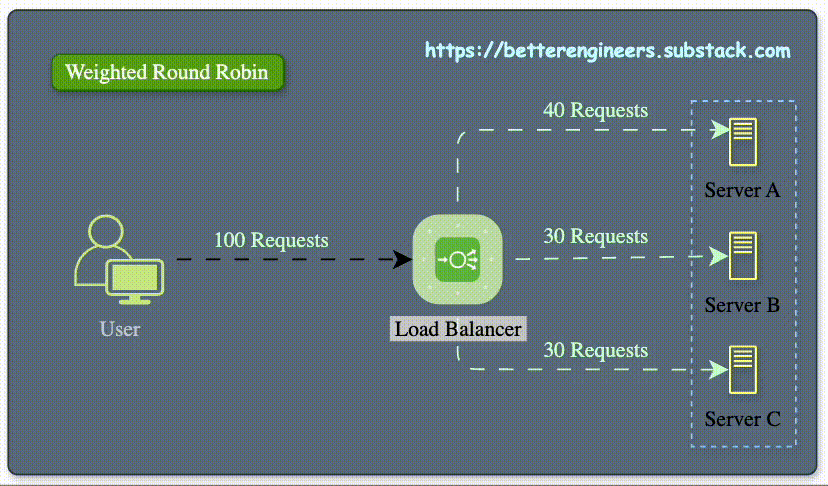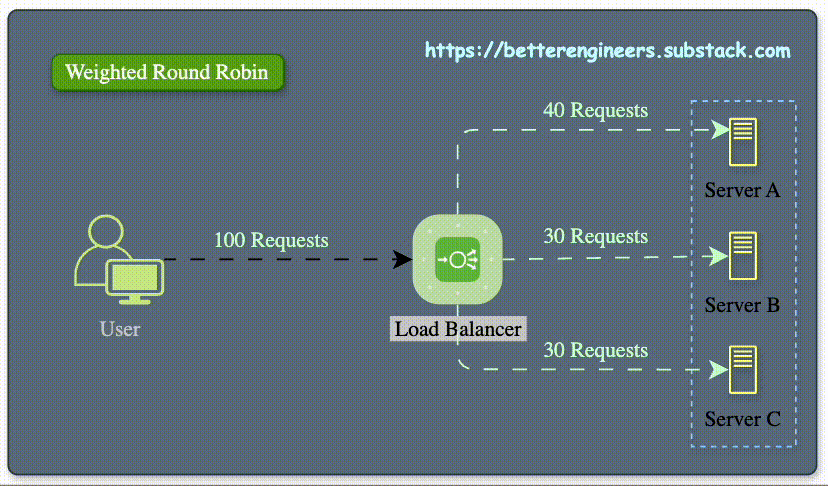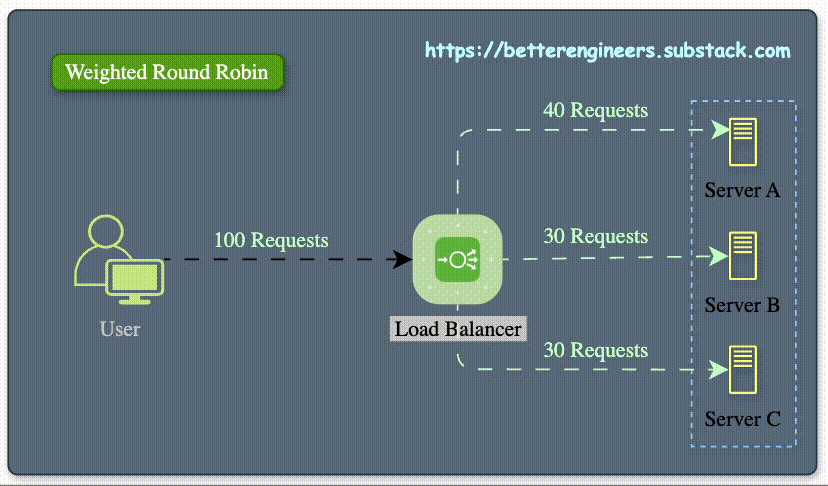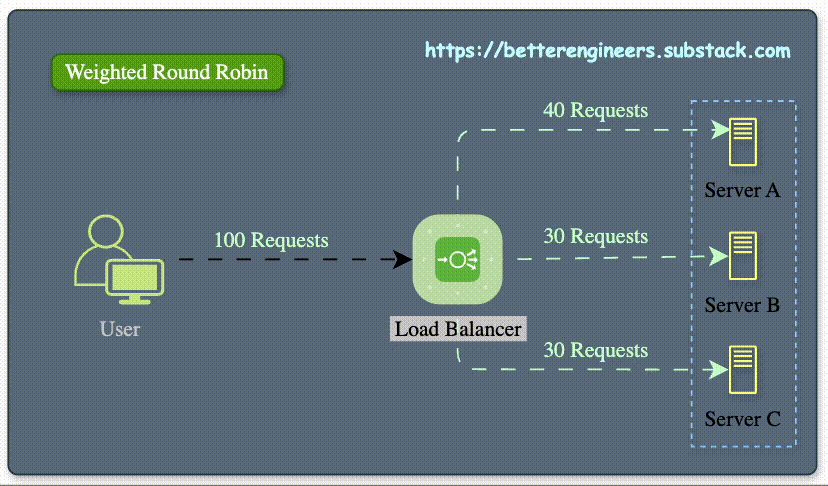
Load Balancer
Load balancing is the method of distributing network traffic equally across a pool of resources that support an application. Modern applications must process millions of users simultaneously and return the correct text, videos, images, and other data to each user in a fast and reliable manner. To handle such high volumes of traffic, most applications have many resource servers with duplicate data between them. A load balancer is a device that sits between the user and the server group and acts as an invisible facilitator, ensuring that all resource servers are used equally.

Scatter and Gather
The Scatter-Gather Pattern is a messaging and processing pattern often used in distributed systems to split work into parallel tasks and then merge the results.
Here’s how it works:
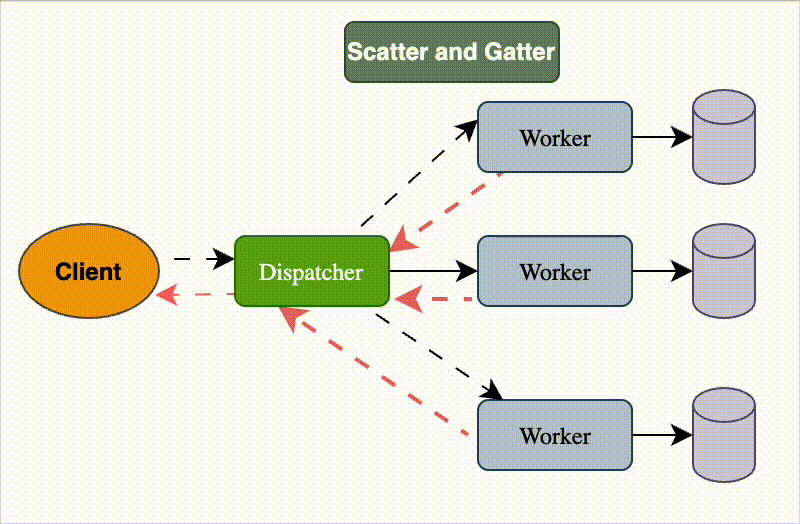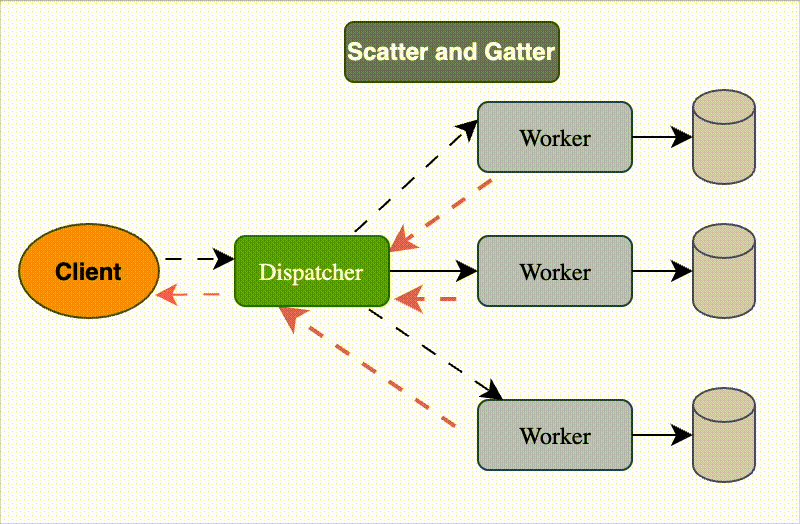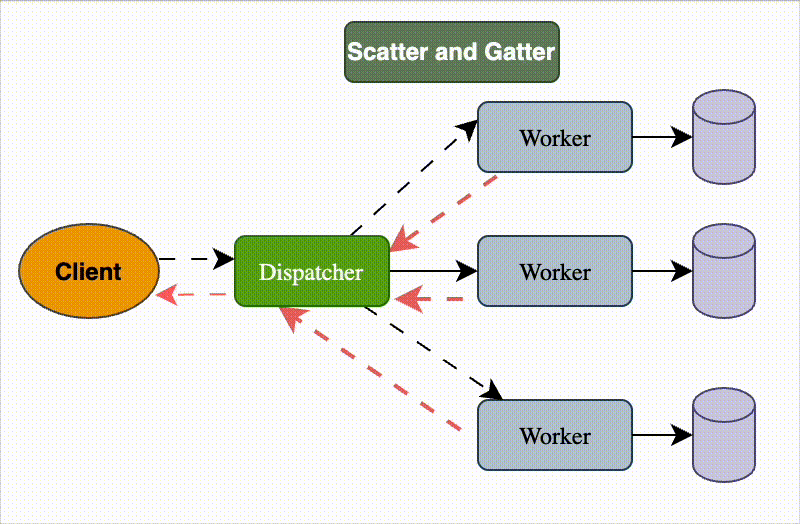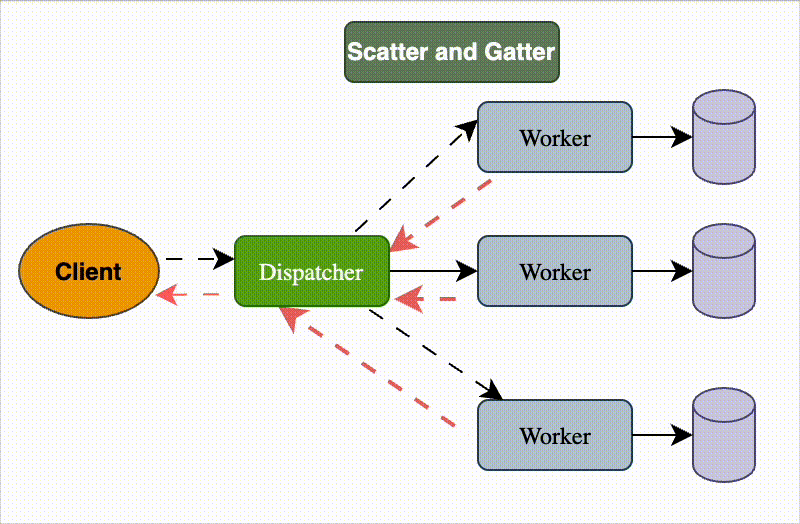
1. Scatter phase
A request is split into multiple sub-requests.
These sub-requests are sent in parallel to multiple services, nodes, or workers.
Each worker processes only its assigned part.
Example:
If you’re building a search engine that queries multiple data sources (e.g., SQL, NoSQL, API), the search query is sent to all of them at once.
2. Gather phase
The system collects results from all workers.
The responses are combined into a single unified result.
Sometimes this involves aggregation, filtering, or sorting.
Example:
The search engine collects all partial results from the data sources, merges them, removes duplicates, and ranks them.
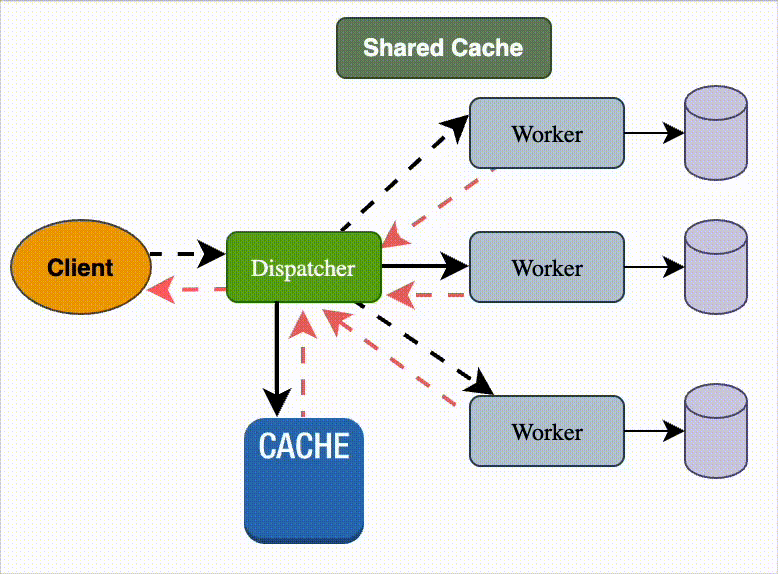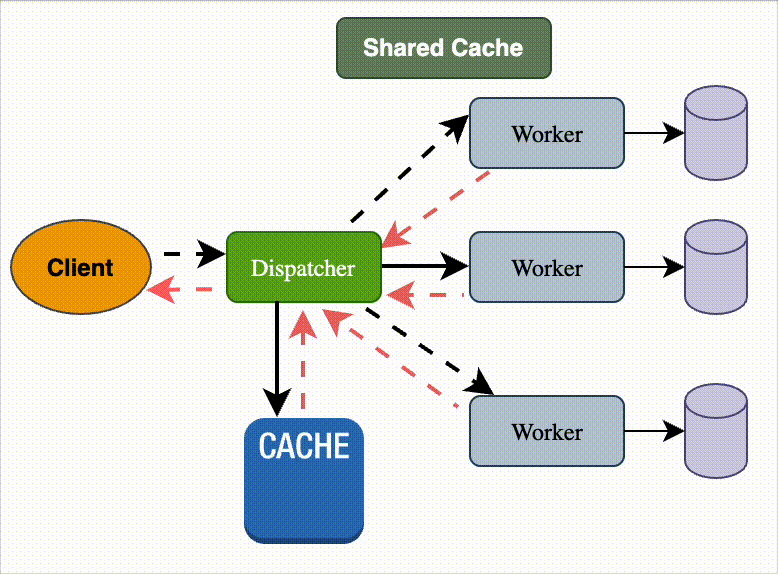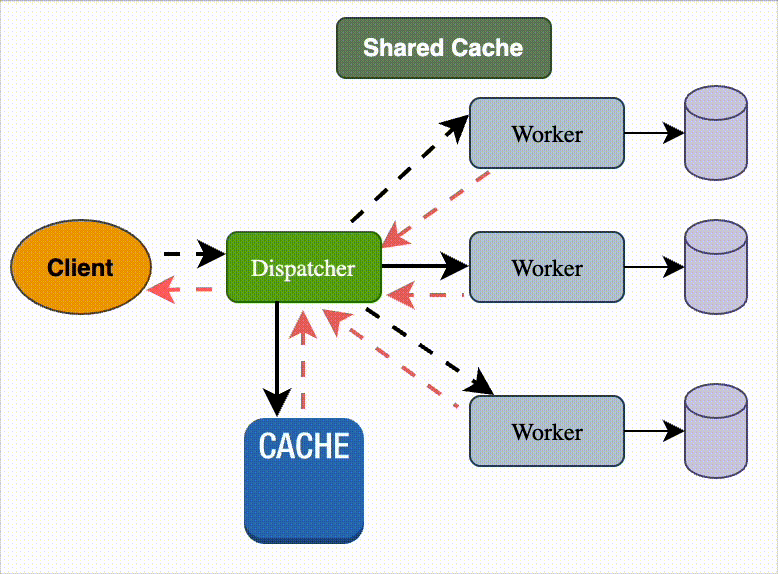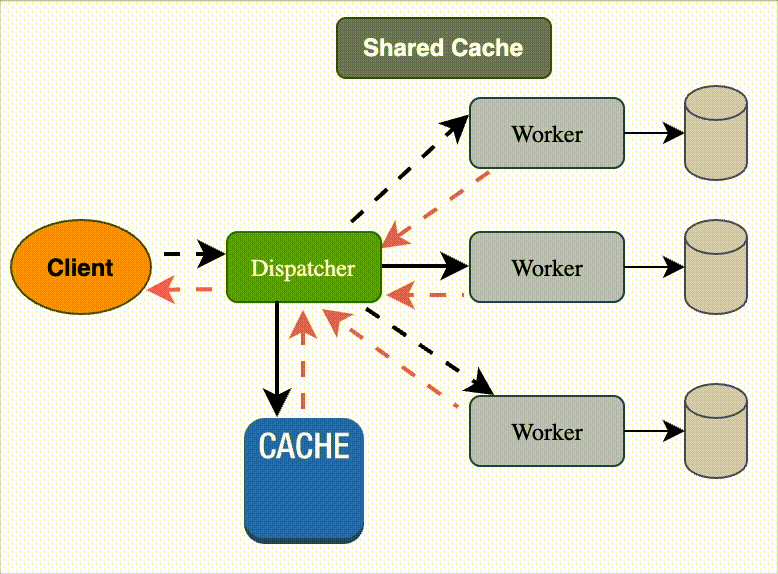
Result Cache
What it is
A cache layer stores results of expensive computations or queries so that repeated requests can be served faster.
Saves compute cycles, I/O, and latency by avoiding redundant work.
Can be local (in-process), distributed (shared), or global (across regions).
Characteristics
Key-based retrieval: results indexed by input parameters or query hash.
Eviction policies: LRU, LFU, TTL, write-through, or write-behind.
Levels:
Client-side (browser cache)
Mid-tier (CDN, API cache, Redis)
DB query cache (materialized views, memoization).
Real-World Examples
CDNs caching static assets.
Database query caching (MySQL query cache, PostgreSQL materialized views).
Redis/Memcached as distributed caches.
ML inference caches: caching model predictions for common inputs.
Pros
Huge performance boost for repeated workloads.
Reduces load on backend systems.
Cost-effective for read-heavy workloads.
Cons
Stale data if invalidation is not handled correctly.
Cache consistency: ensuring cache reflects true system-of-record state.
Overhead: maintaining and invalidating caches adds complexity.
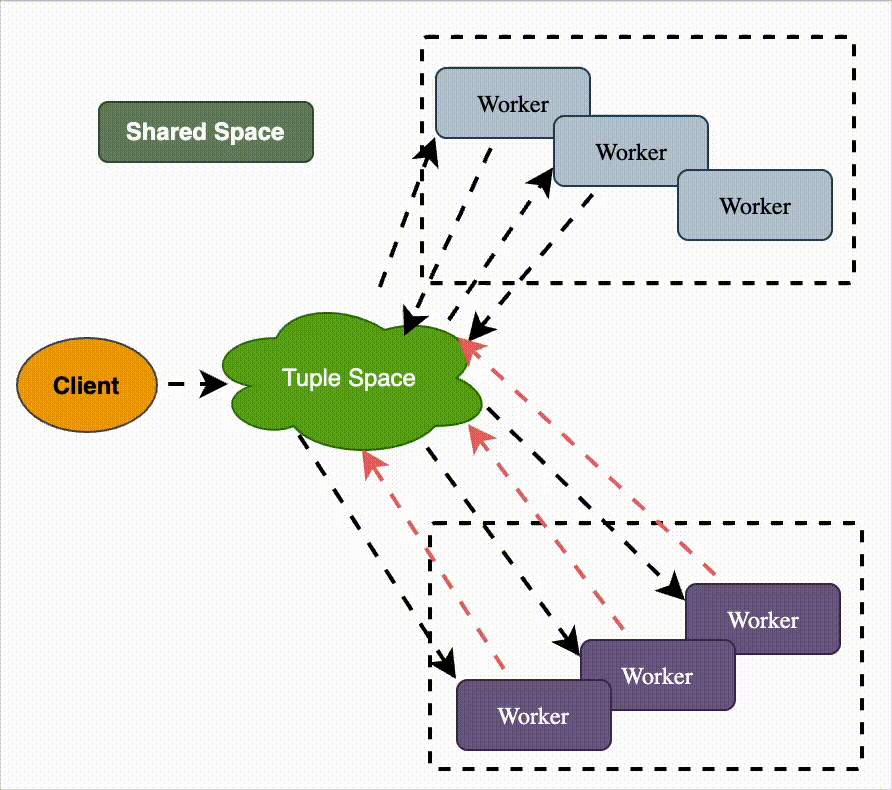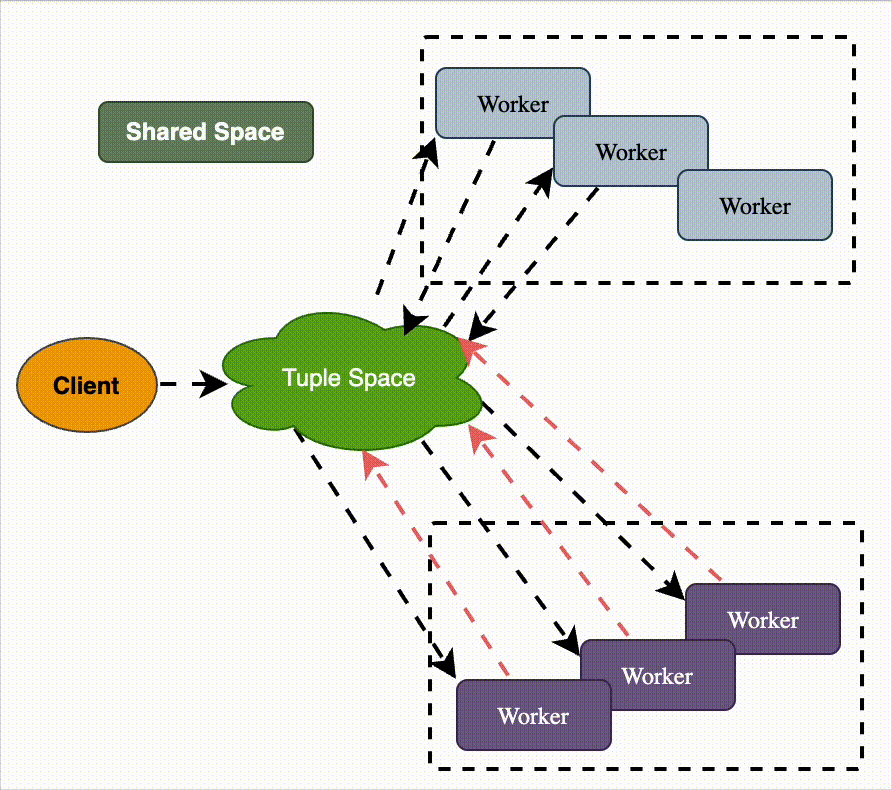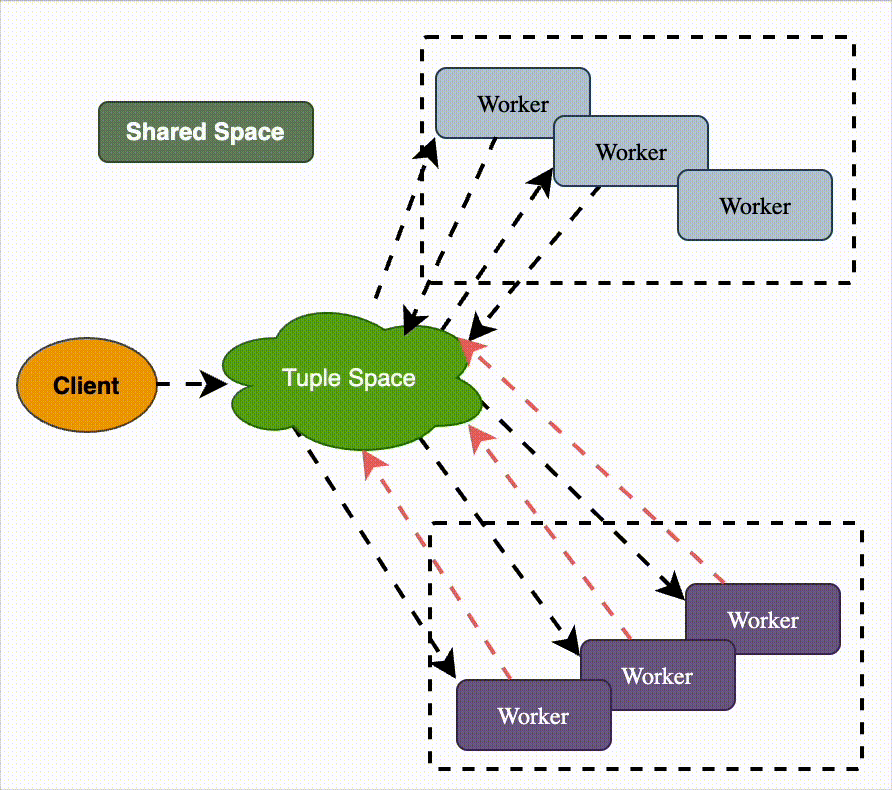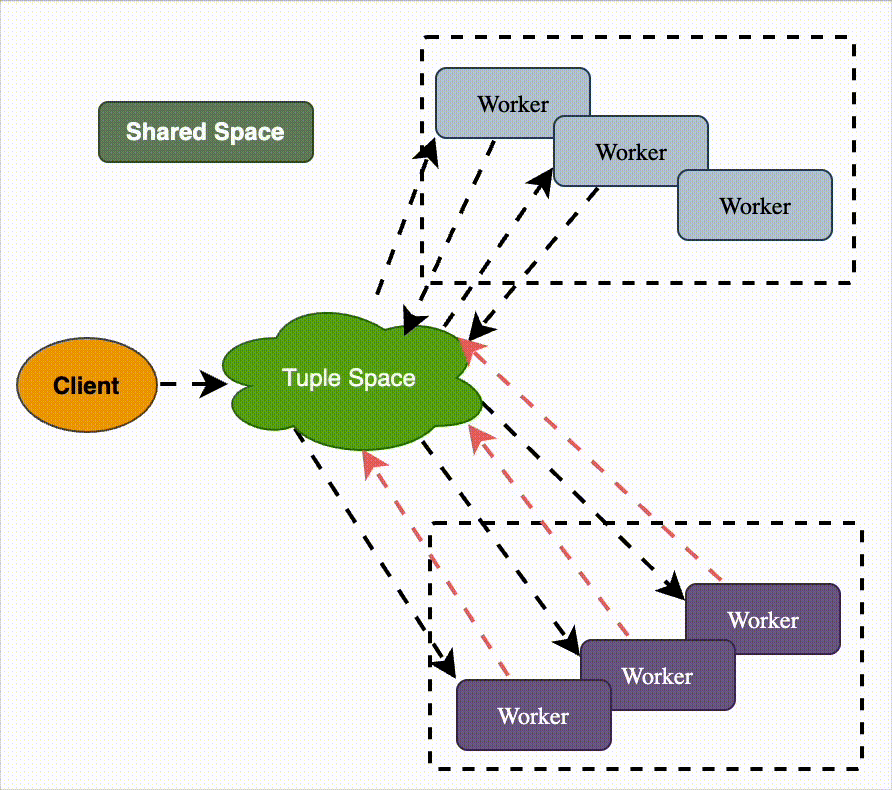
Shared Space
What it is
A shared, concurrent data space acts as the central coordination point between distributed workers.
Workers read, write, and update shared objects in this common space.
The shared space decouples producers and consumers in time, location, and execution order.
Think of it as a blackboard where multiple processes post work items and results.
Characteristics
Decoupled communication: writers don’t need to know readers.
Associative access: workers query the shared space for items matching patterns (e.g., “give me a task with status=ready”).
Coordination mechanism: space acts as queue + storage + synchronization.
Real-World Analogies
Linda Tuple Space (classic model for parallel computing).
JavaSpaces (Jini-based shared object space).
Kubernetes etcd (shared cluster state store).
Redis / Memcached used as a coordination store.
Pros
Loose coupling between producers and consumers.
Natural model for coordination & synchronization.
Workers can join/leave dynamically.
Cons
Contention: shared space can become a bottleneck under high concurrency.
Consistency challenges: concurrent updates need transactions or conflict resolution.
Scalability: naive centralized shared spaces don’t scale well without sharding/partitioning.
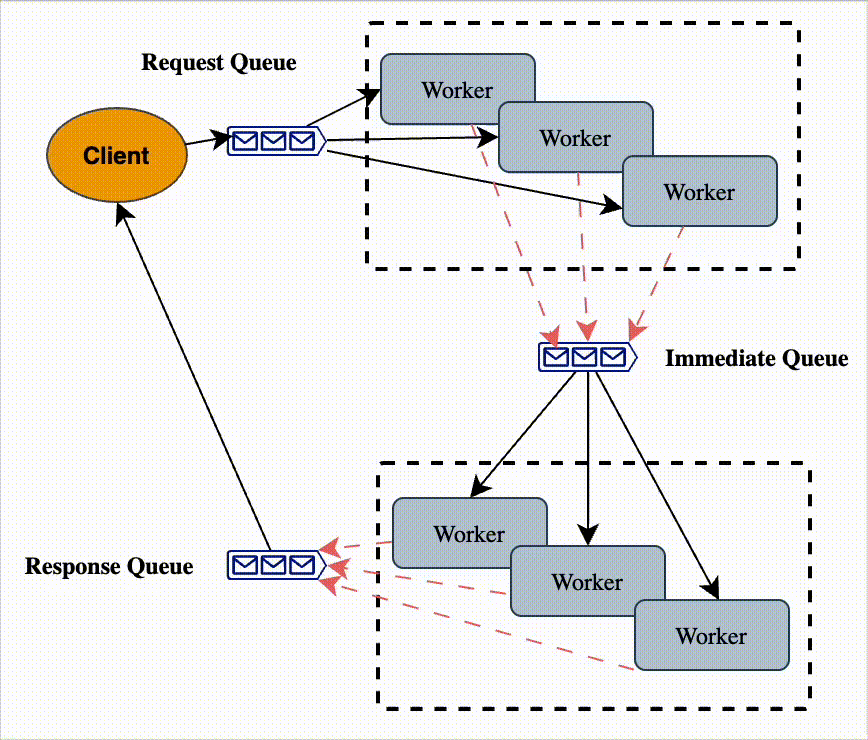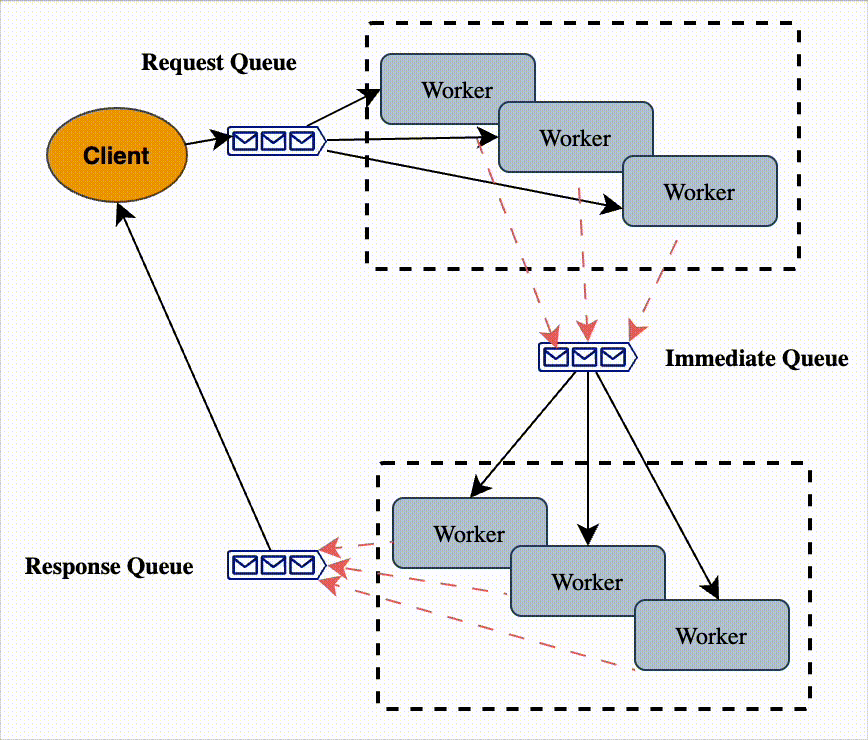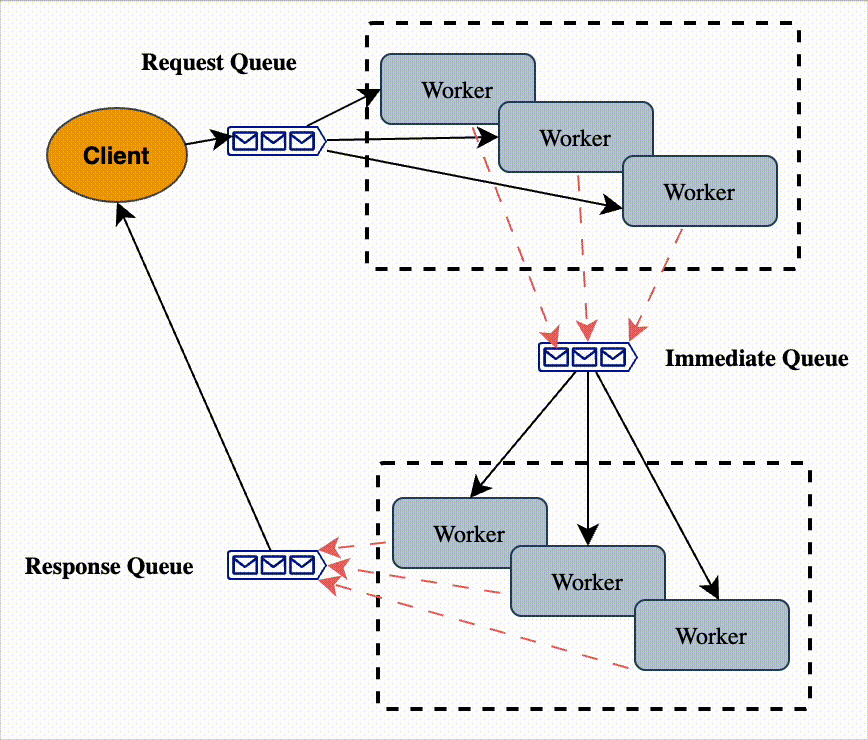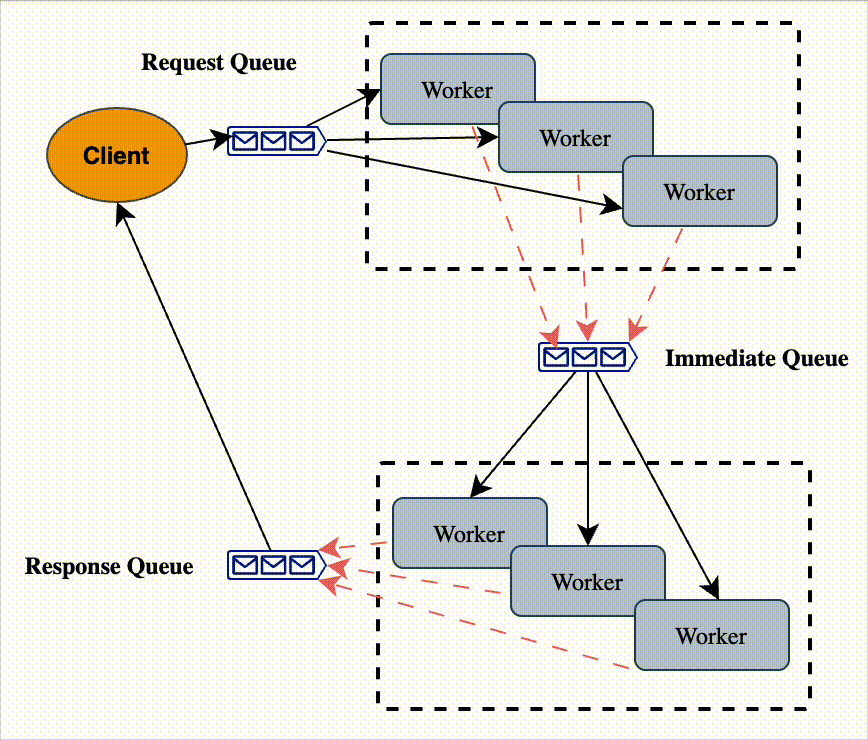
Pipe and Filter
A Pipe and Filter architecture breaks down a task into a series of processing steps called filters.
Each filter takes input, processes it, and produces output.
The pipes connect filters, passing data between them.
Characteristics
Filters
Independent, reusable processing units.
Do not share state; communicate only through data passed in/out.
Examples: parsing, transforming, aggregating, validating.
Pipes
The connectors between filters.
Can be in-memory streams, message queues, files, or sockets.
Ensure data flows in order, without requiring filters to know about each other.
Data Flow Orientation
Data flows through the pipeline.
Filters can be chained or rearranged to form different pipelines.
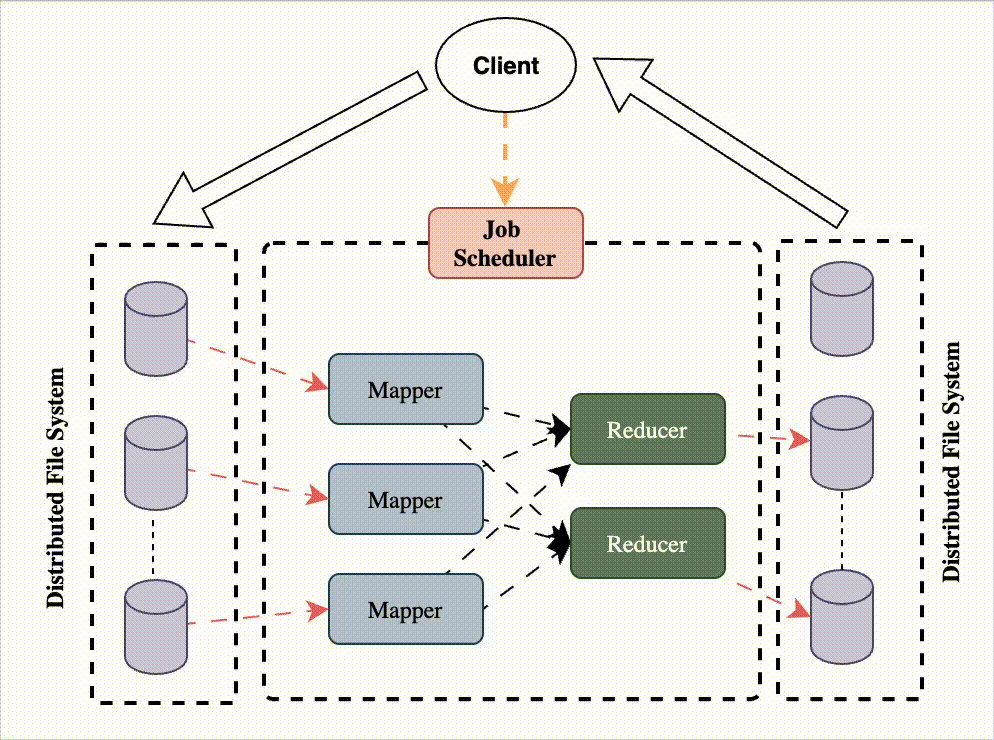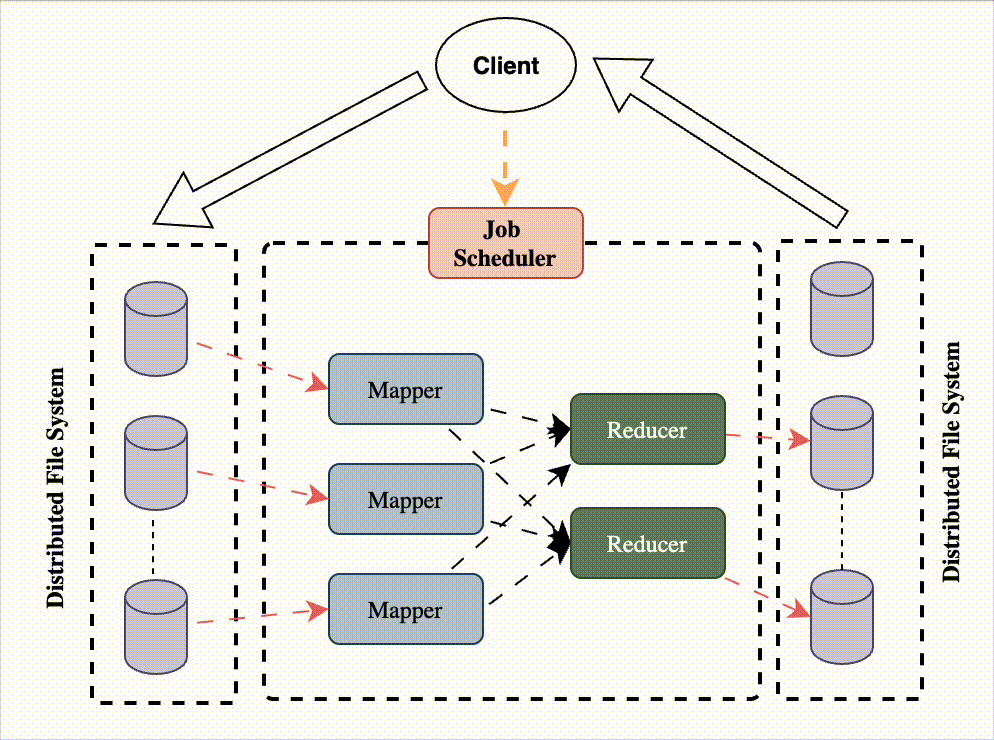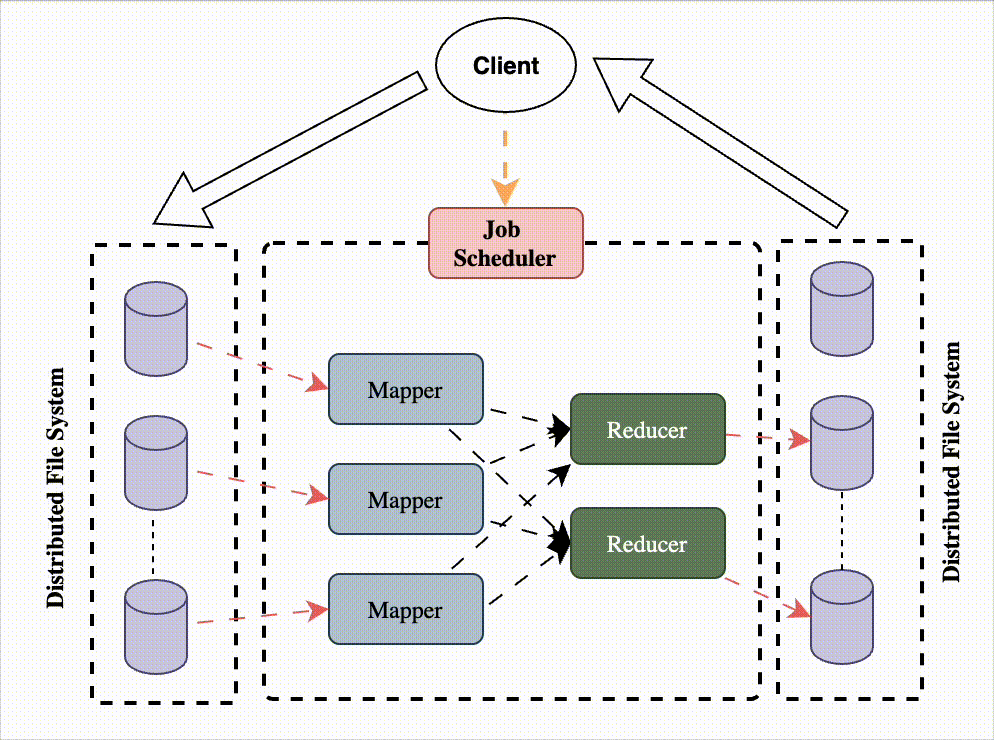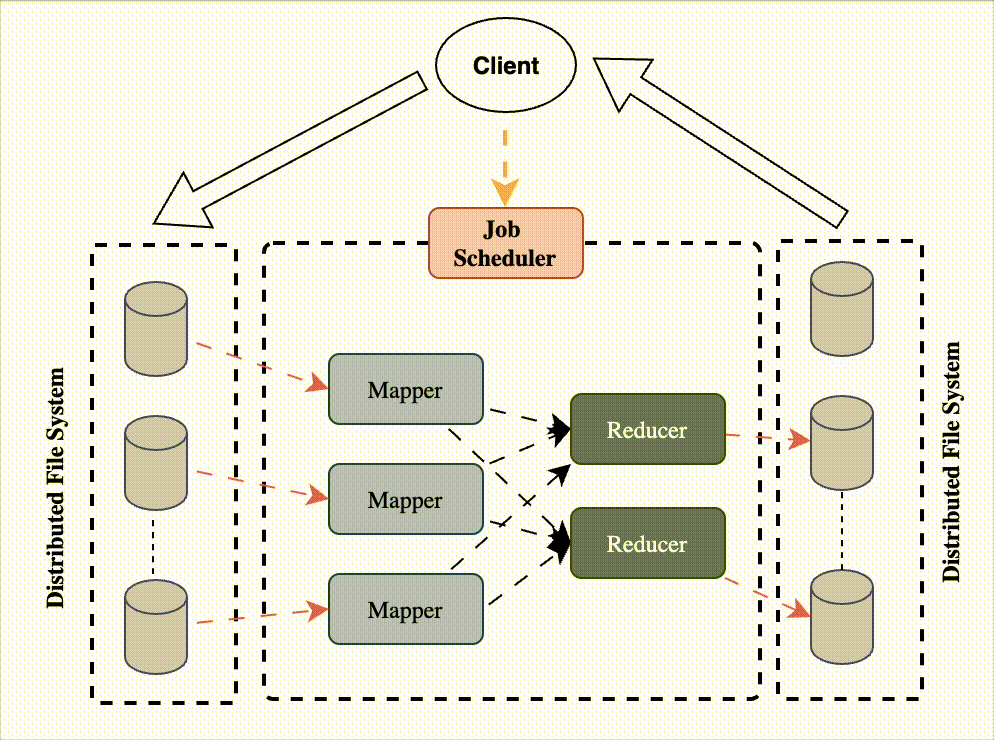
Map Reduce
What it is
Two-phase distributed computation:
Map: split input into key-value pairs.
Reduce: aggregate results by key.
Characteristics
Input is partitioned and distributed across workers.
Final results are combined in a deterministic way.
Ideal for batch analytics and ETL.
Example Systems
Hadoop MapReduce
Early Google MapReduce paper
Pros
Simple programming model.
Scales to petabytes of data.
Cons
Disk-heavy (batch mode).
Limited to map/reduce style problems.
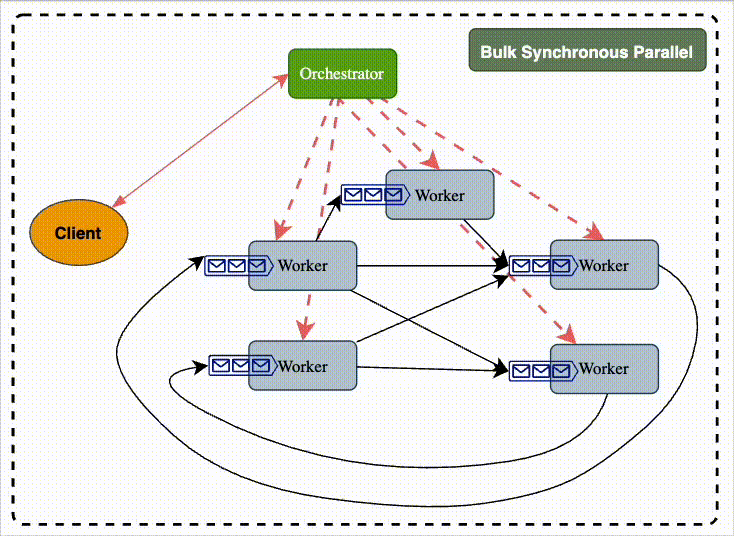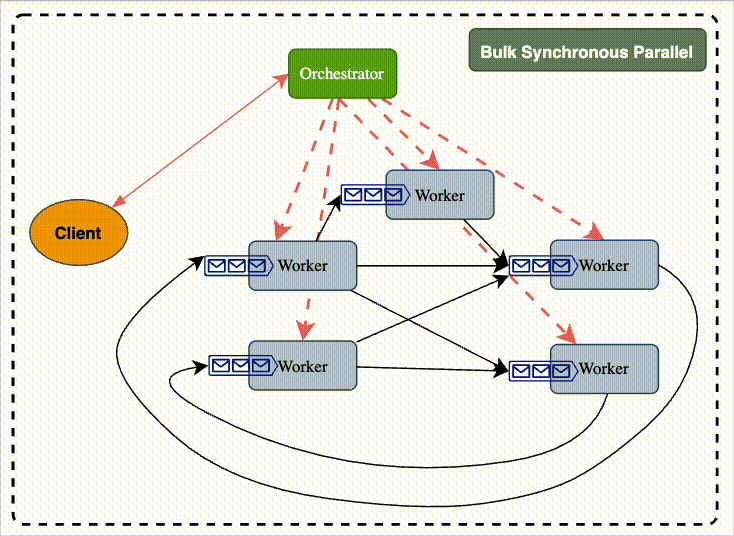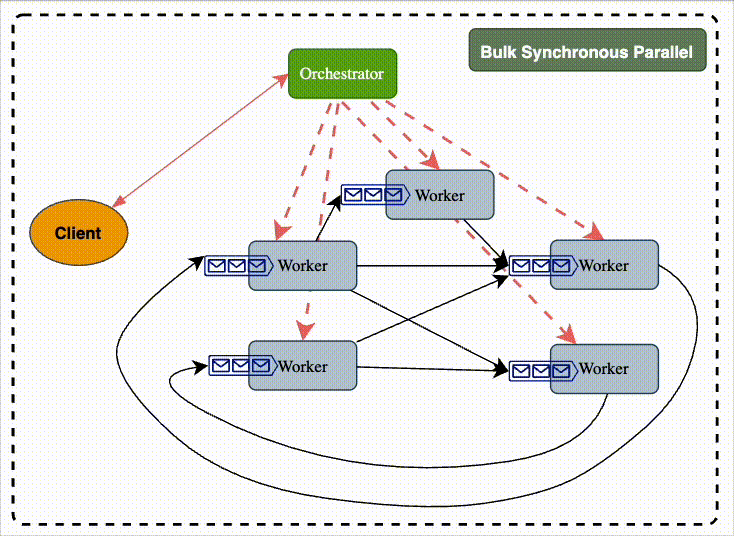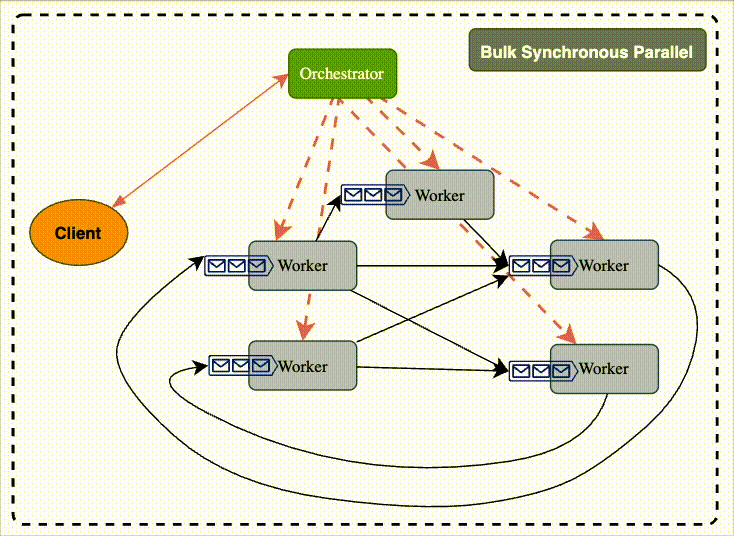
Bulk Synchronous Parallel
What it is
Workers execute tasks in lockstep “supersteps”.
Each superstep = (compute locally → communicate with peers → synchronize).
Characteristics
Coordination through barriers: all workers must finish one superstep before the next starts.
Data is exchanged at the end of each step.
Used heavily in graph algorithms (PageRank, shortest paths).
Example Systems
Google Pregel
Apache Giraph, Hama
Pros
Simple to reason about mathematically.
Great for algorithms where global synchronization is natural.
Cons
Idle resources: fast workers wait for slow ones (“stragglers”).
Less efficient for heterogeneous tasks.
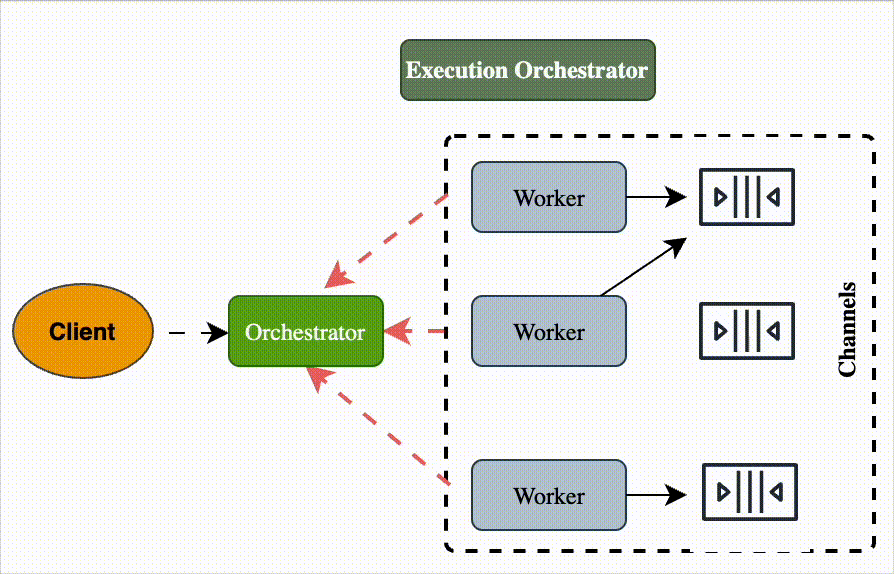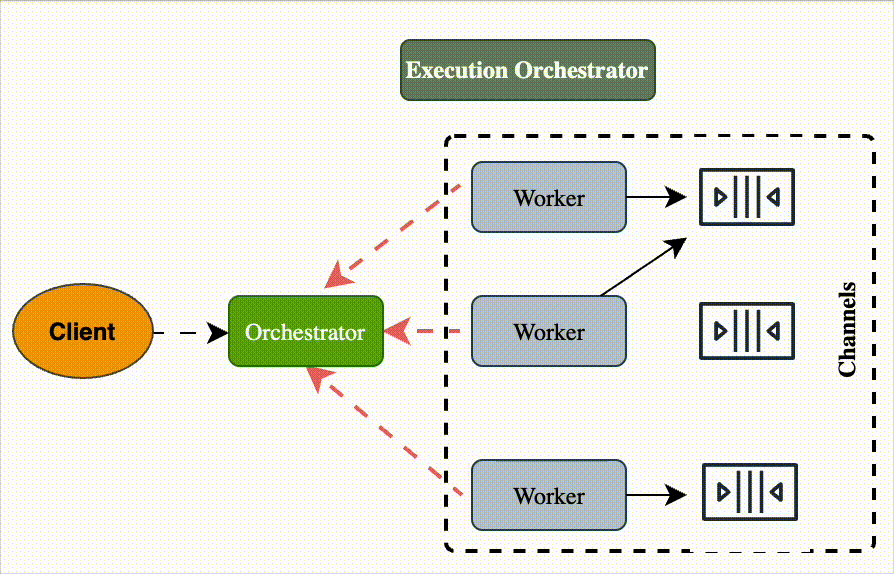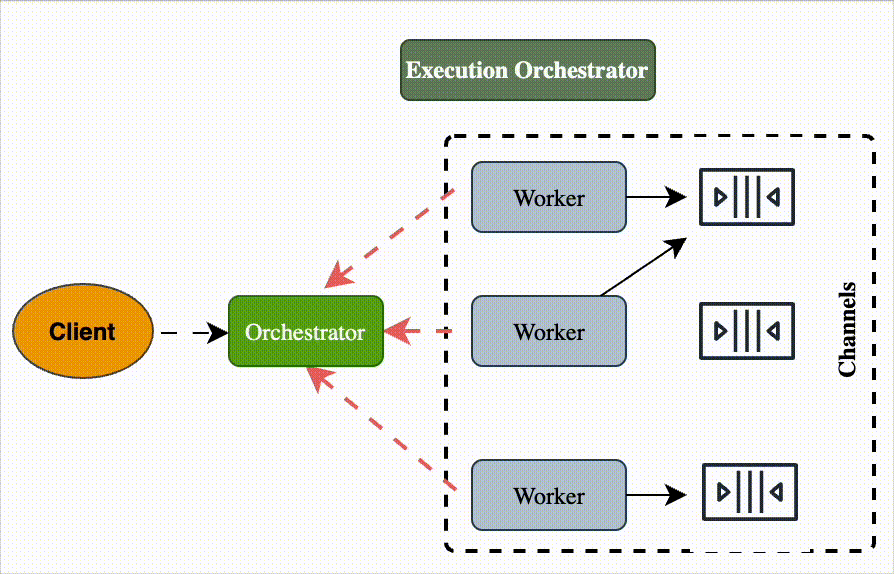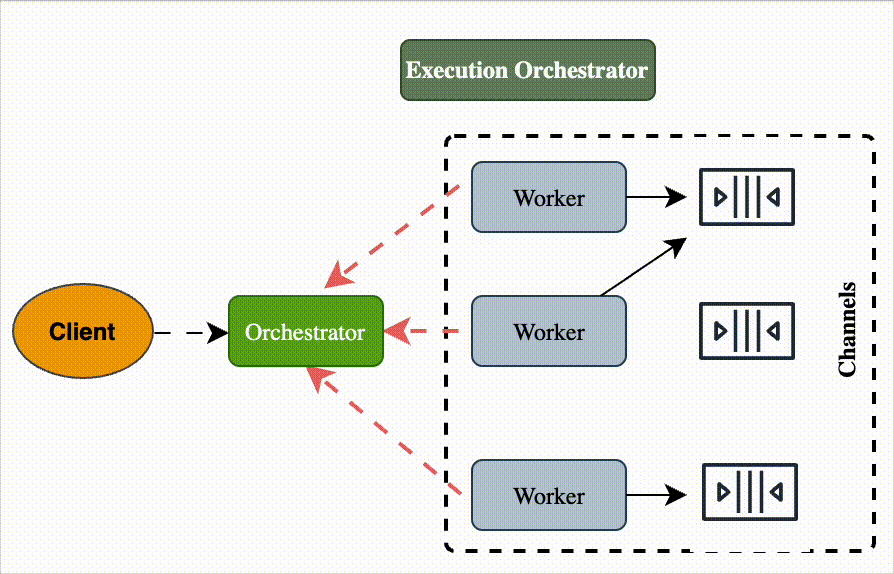
Execution Orchestrator
What it is
A central controller (orchestrator) that manages a set of tasks modeled as a dependency graph (DAG).
The orchestrator decides which tasks are ready to run, and assigns them to stateless workers.
Characteristics
Asynchronous execution: workers process tasks independently, report back to orchestrator.
Fault handling: retries, rollbacks, compensation logic are orchestrated centrally.
State tracking: orchestrator keeps full workflow state, dependencies, and progress logs.
Example Systems
Microsoft Dryad
Netflix Conductor
Temporal / Cadence
AWS Step Functions
Pros
Strong control and visibility.
Good for multi-step workflows, audits, SLAs.
Cons
Orchestrator can be a scaling bottleneck if not sharded.
Adds complexity compared to pure pub/sub.