
System Design: The Distributed Task Scheduler
A task is a piece of computational work that requires resources (CPU time, memory, storage, network bandwidth, and so on) for some specified time.

Educative.io (Collaboration)
Educative is turning 10, and to celebrate, I am partnering with them to give 3 of you a FREE 1-Year Subscription to their platform! Whether you want to level up in tech, switch careers, or sharpen your skills, this is your chance.

To enter:
1️⃣ Like this post and re-stack
2️⃣ Follow me on LinkedIn
3️⃣ Refer 3 friends who’d love to learn too!
This giveaway will be open for two weeks starting today, Aug 13, 2025, and I will randomly select 3 winners who meet all the requirements after the contest closes at 11:59 PM WAT on Sunday, Aug 15, 2025.
Big thanks to Educative for 10 years of helping devs grow.
Good luck, everyone! 🚀
What is a task scheduler?
A task is a piece of computational work that requires resources (CPU time, memory, storage, network bandwidth, and so on) for some specified time. For example, uploading a photo or a video on Facebook or Instagram consists of the following background tasks:
Encode the photo or video in multiple resolutions.
Validate the photo or video to check for content monetization copyrights, and many more.
The successful execution of all the above tasks makes the photo or video visible. However, a photo and video uploader does not need to stop the above tasks to complete.
Another example is when we post a comment on Facebook. We don’t hold the comment poster until that comment is delivered to all the followers. That delivery is delegated to an asynchronous task scheduler to do offline.
In a system, many tasks contend for limited computational resources. A system that mediates between tasks and resources by intelligently allocating resources to tasks so that task-level and system-level goals are met is called a task scheduler.
When to use a task scheduler
A task scheduler is a critical component of a system for getting work done efficiently. It allows us to complete a large number of tasks using limited resources. It also aids in fully utilizing the system’s resources, provides users with an uninterrupted execution experience, and so on. The following are some of the use cases of task scheduling:
Single-OS-based node: It has many processes or tasks that contend for the node’s limited computational resources. So, we could use a local OS task scheduler that efficiently allocates resources to the tasks. It uses multi-feedback queues to pick some tasks and runs them on some processor.
Cloud computing services: Where there are many distributed resources and various tasks from multiple tenants, there is a strong need for a task scheduler to utilize cloud computing resources efficiently and meet tenants’ demands. A local OS task scheduler isn’t sufficient for this purpose because the tasks are in the billions, the source of the tasks is not single, and the resources to manage are not in a single machine. We have to go for a distributed solution.
Large distributed systems: In this system, many tasks run in the background against a single request by a user. Consider that there are millions to billions of users of a popular system like Facebook, WhatsApp, or Instagram. These systems require a task scheduler to handle billions of tasks. Facebook schedules its tasks against billions of parallel asynchronous requests by its users using Async.
Note: Async is Facebook’s own distributed task scheduler that schedules all its tasks. Some tasks are more time-sensitive, like the tasks that should run to notify the users that the livestream of an event has started. It would be pointless if the users received a notification about the livestream after it had finished. Some tasks can be delayed, like tasks that make friend suggestions to users. Async schedules tasks based on appropriate priorities.
Distributed task scheduling
The process of deciding and assigning resources to the tasks in a timely manner is called task scheduling. The visual difference between an OS-level task scheduler and a data center-level task scheduler is shown in the following illustration:
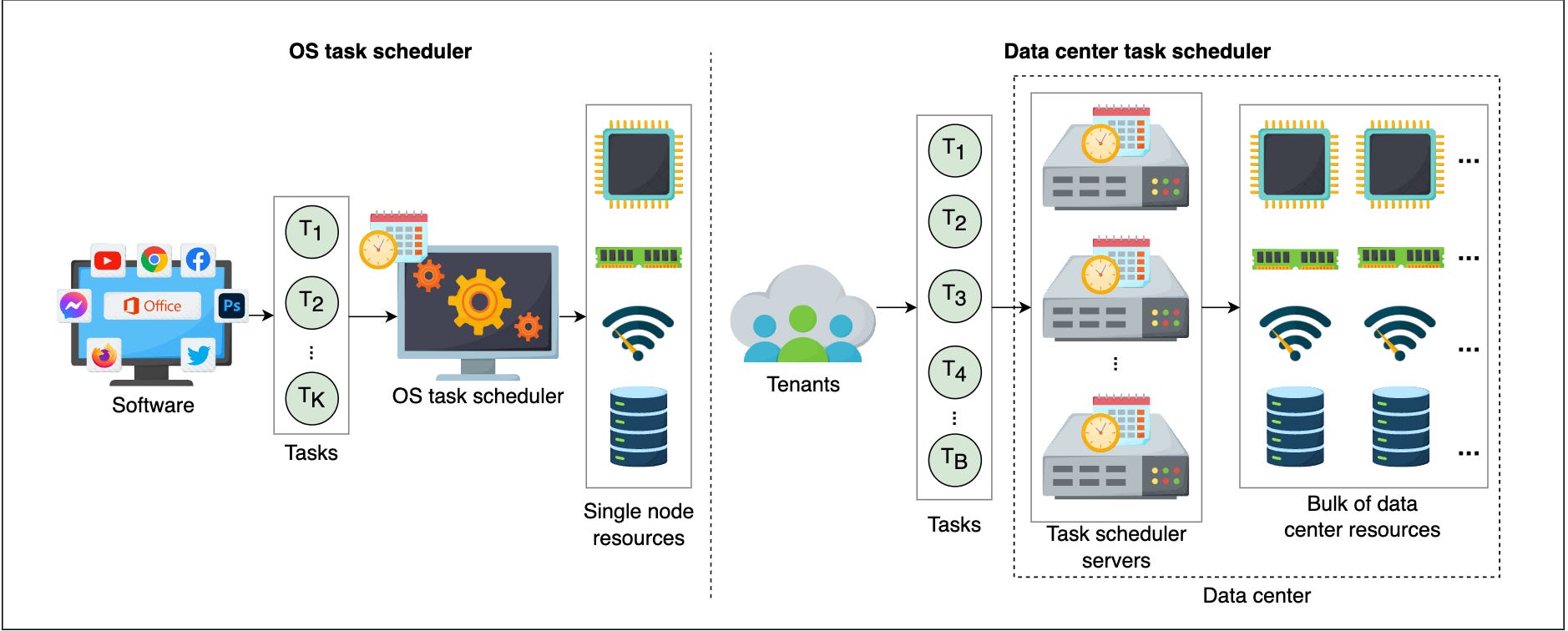
The OS task scheduler schedules a node’s local tasks or processes on that node’s computational resources. At the same time, the data center’s task scheduler schedules billions of tasks coming from multiple tenants that use the data center’s resources.
Our goal is to design a task scheduler similar to the data center-level task scheduler where the following is considered:
Tasks will come from many different sources, tenants, and sub-systems.
Many resources will be dispersed in a data center (or maybe across many data centers).
The above two requirements make the task scheduling problem challenging. We’ll design a distributed task scheduler that can handle all these tasks by making it scalable, reliable, and fault-tolerant.
How will we design a task scheduling system?
We have divided the design of the task scheduler into four lessons:
Requirements: We’ll identify the functional and non-functional requirements of a task scheduling system in this lesson.
Design: This lesson will discuss the system design of our task scheduling system and explores the components of the system and database schema.
Design considerations: In this lesson, we’ll highlight some design factors, such as task prioritization, resource optimization, and so on.
Evaluation: We’ll evaluate our design of task scheduler based on our requirements.
Let’s start by understanding the requirements of a task scheduling system.
Requirements of a Distributed Task Scheduler's Design
Learn about the functional and non-functional requirements of the task scheduler.
Requirements
Let’s start by understanding the functional and non-functional requirements for designing a task scheduler.
Functional requirements
The functional requirements of the distributed task scheduler are as follows:
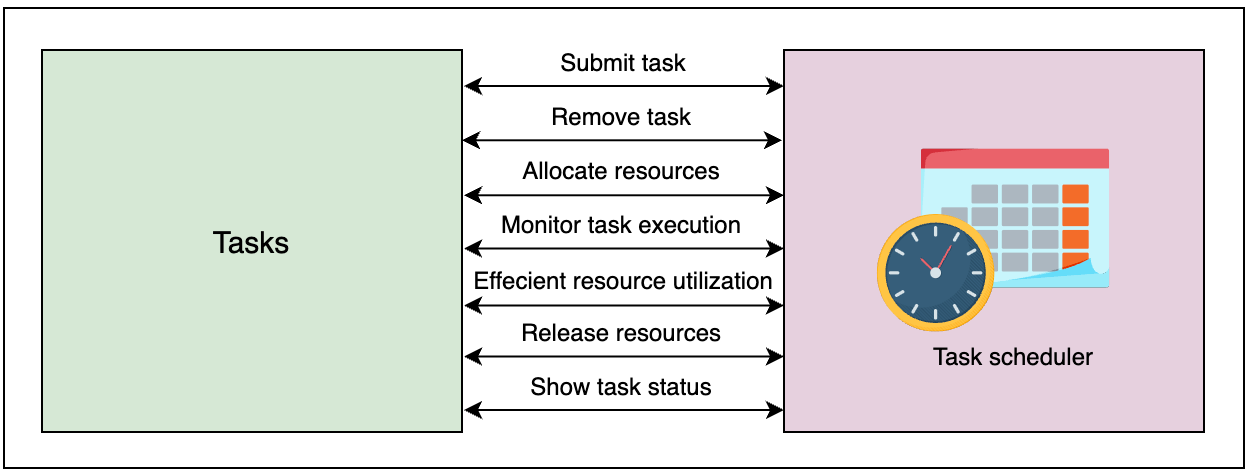
Submit tasks: The system should allow the users to submit their tasks for execution.
Allocate resources: The system should be able to allocate the required resources to each task.
Remove tasks: The system should allow the users to cancel the submitted tasks.
Monitor task execution: The task execution should be adequately monitored and rescheduled if the task fails to execute.
Efficient resource utilization: The resources (CPU and memory) must be used efficiently in terms of time, cost, and fairness. Efficiency means that we do not waste resources. For example, if we allocate a heavy resource to a light task that can easily be executed on a cheap resource, it means that we have not efficiently utilized our resources. Fairness is all tenants’ ability to get the resources with equally likely probability in a certain cost class.
Release resources: After successfully executing a task, the system should take back the resources assigned to the task.
Show task status: The system should show the users the current status of the task.
Building blocks we will use
We’ll utilize the following building blocks in the design of our task scheduling system:
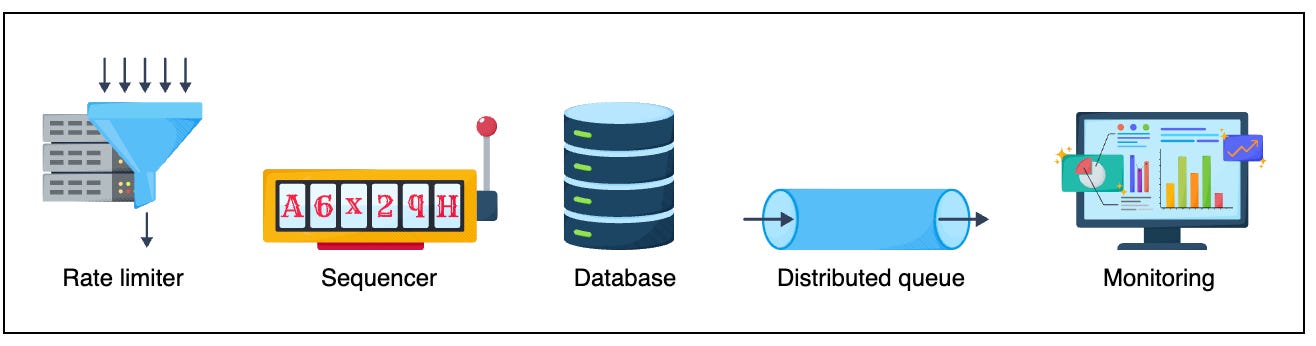
Building blocks of a task schedular
Rate limiter is required to limit the number of tasks so that our system is reliable.
A sequencer is needed to uniquely identify tasks.
Database(s) are used to store task information.
A distributed queue is required to arrange tasks in the order of execution.
Monitoring is essential to check the health of the resources and to detect failed tasks to provide reliable service to the users.
Design of a Distributed Task Scheduler
Keep reading with a 7-day free trial
Subscribe to Better Engineers to keep reading this post and get 7 days of free access to the full post archives.