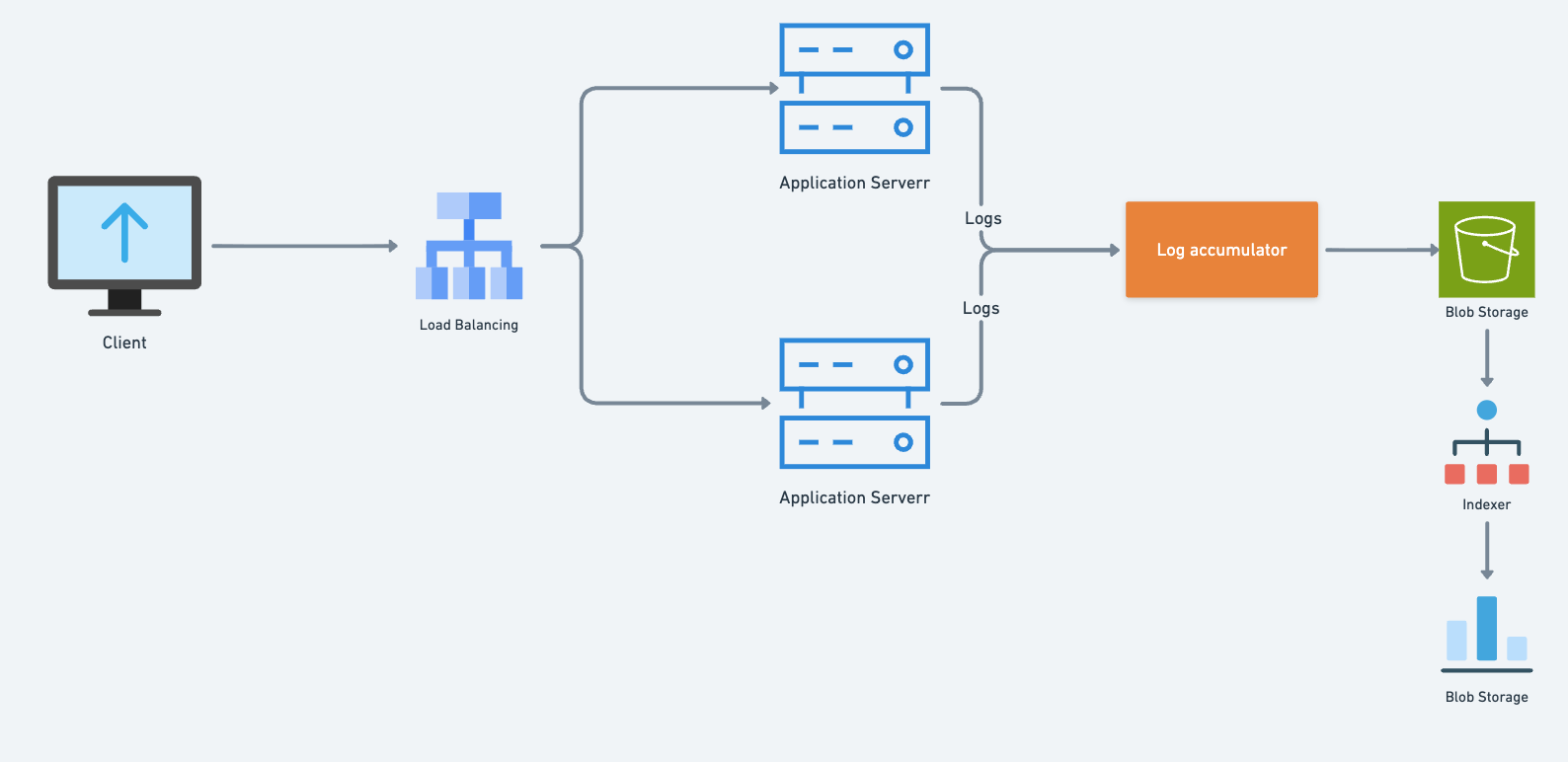
Designing a Robust Distributed Logging System for Modern Applications

In today’s distributed world, applications rarely run on a single machine. Microservices, containerized workloads, and cloud-native architectures introduce both scalability and complexity. One major challenge that arises in such environments is logging. How do you capture, aggregate, and analyze logs spread across thousands of instances running in multiple regions?
A distributed logging system solves this challenge by ensuring that every event in your system can be tracked, stored, and queried efficiently—without losing data or overloading infrastructure. Let’s walk through the design principles, architecture, and considerations for building a robust distributed logging system.
System Design Refresher
Why Do We Need Distributed Logging?
Scalability: Traditional log files on a single machine don’t scale when you’re running hundreds or thousands of services.
Centralization: Logs scattered across nodes make it difficult to debug issues or trace user requests.
Reliability: Systems must handle failures gracefully without losing logs.
Observability: Logging forms the foundation for monitoring, alerting, and root cause analysis.
In essence, distributed logging is not just about collecting logs—it’s about making them usable at scale.
Key Components of a Distributed Logging System
A well-designed logging pipeline typically has four stages: