
What is the CAP theorem?

Coined in 1998 by Prof. Eric Brewer of the University of California, Berkeley, the CAP theorem states the following: “In any distributed database design, in the face of Partition Tolerance, you can choose to design for either Consistency (CP) or Availability (AP). You cannot have both.”
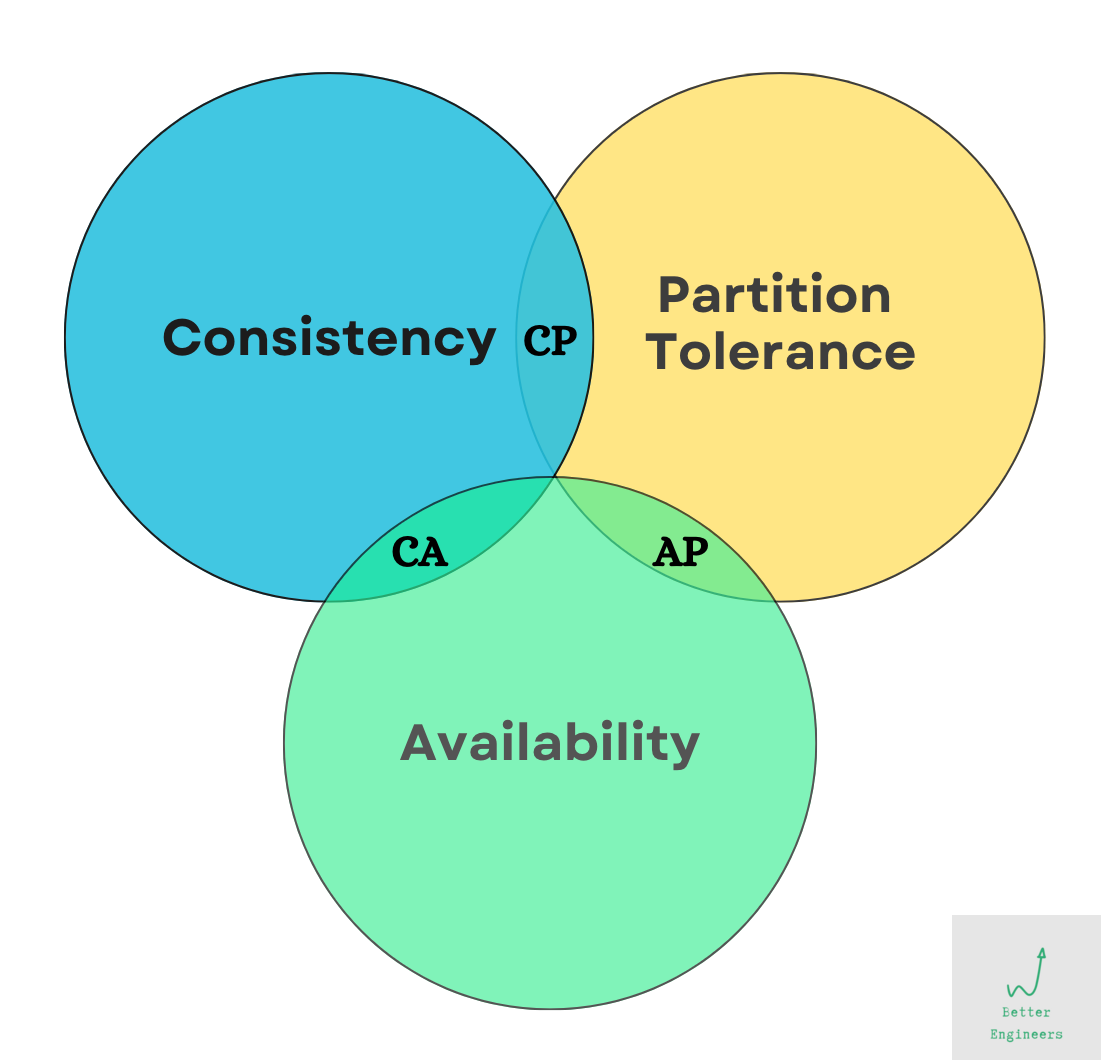
Consistency
Consistency means that all clients see the same data at…
Keep reading with a 7-day free trial
Subscribe to Better Engineers to keep reading this post and get 7 days of free access to the full post archives.