


What is a Vector Database? How Does it Work

Last month Refreshers :
What is a Vector Database? How Does it Work? Use Cases + Examples
Vector databases store high-dimensional data as vectors, allowing for efficient similarity search and retrieval. Unlike traditional databases that store scalar data (like integers or strings), vector databases are optimized for handling the complex, high-dimensional data produced and utilized by AI and ML models. This enables applications to perform fast and accurate searches based on vector similarity, which is crucial for many tasks such as image recognition, text embedding, and other AI-driven applications.
What is a Vector Database?
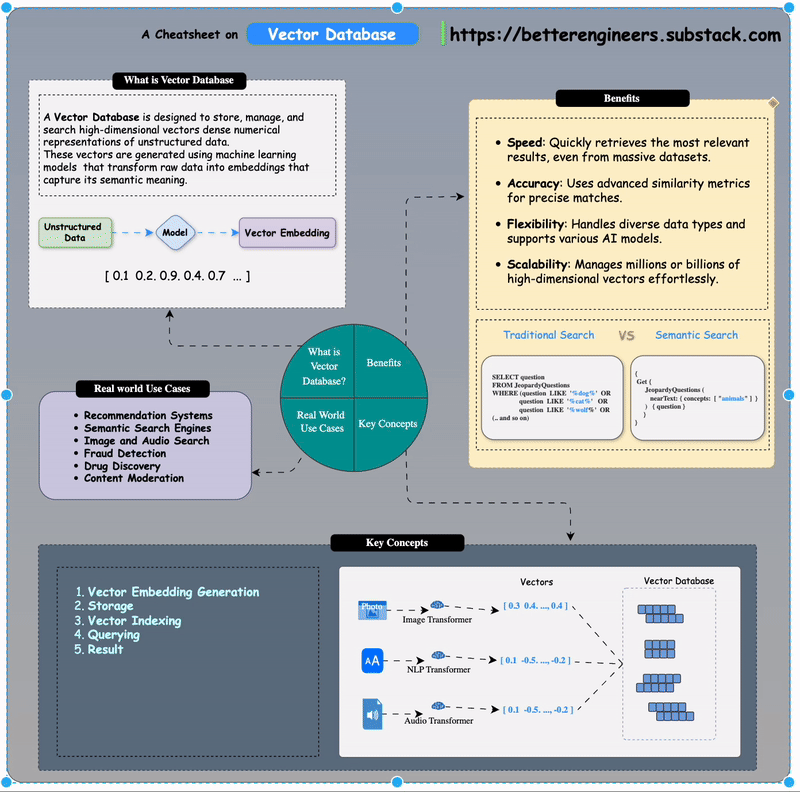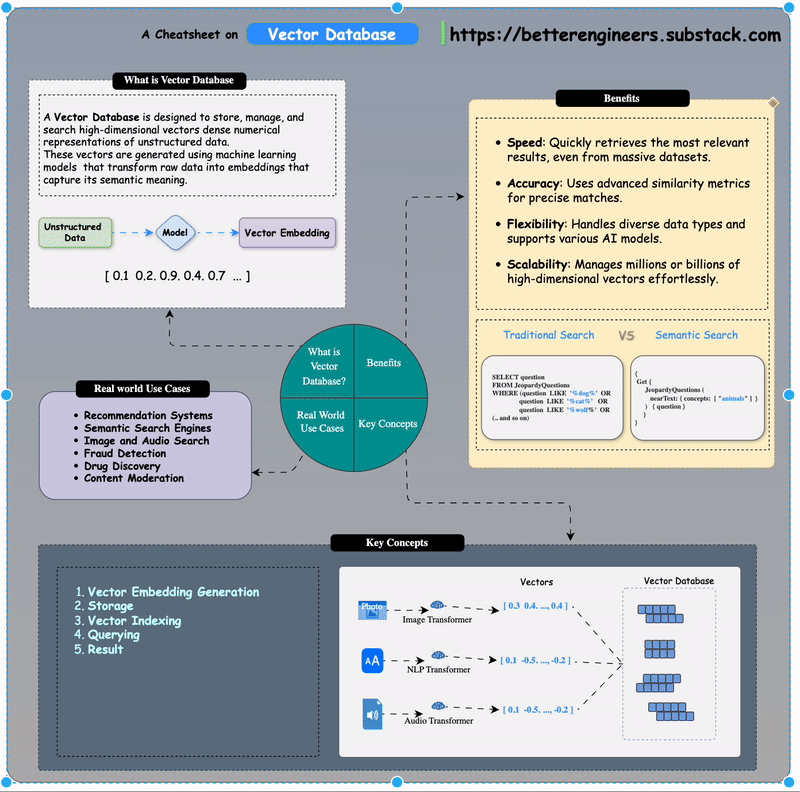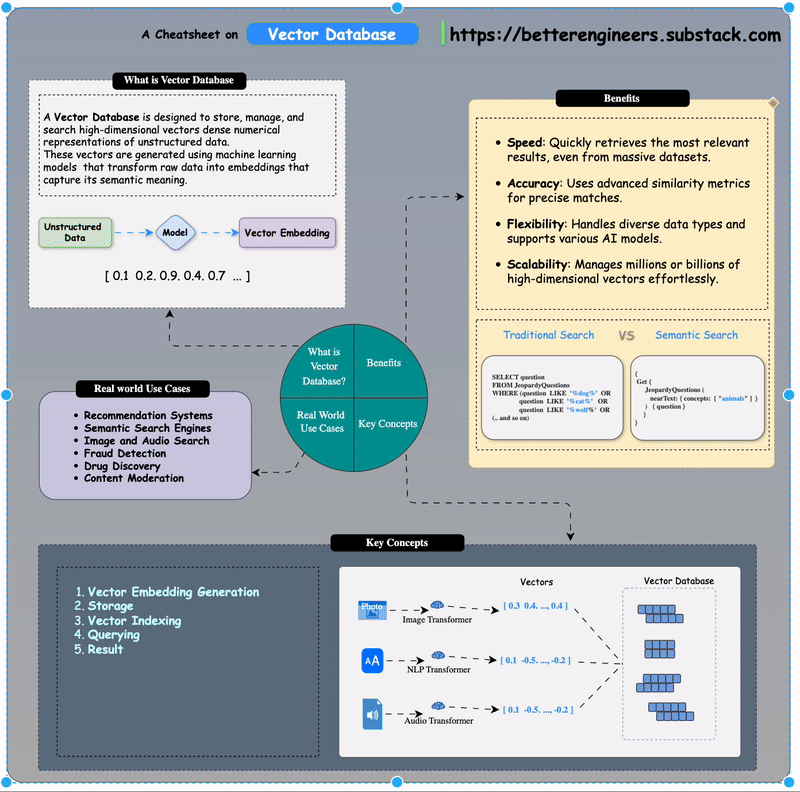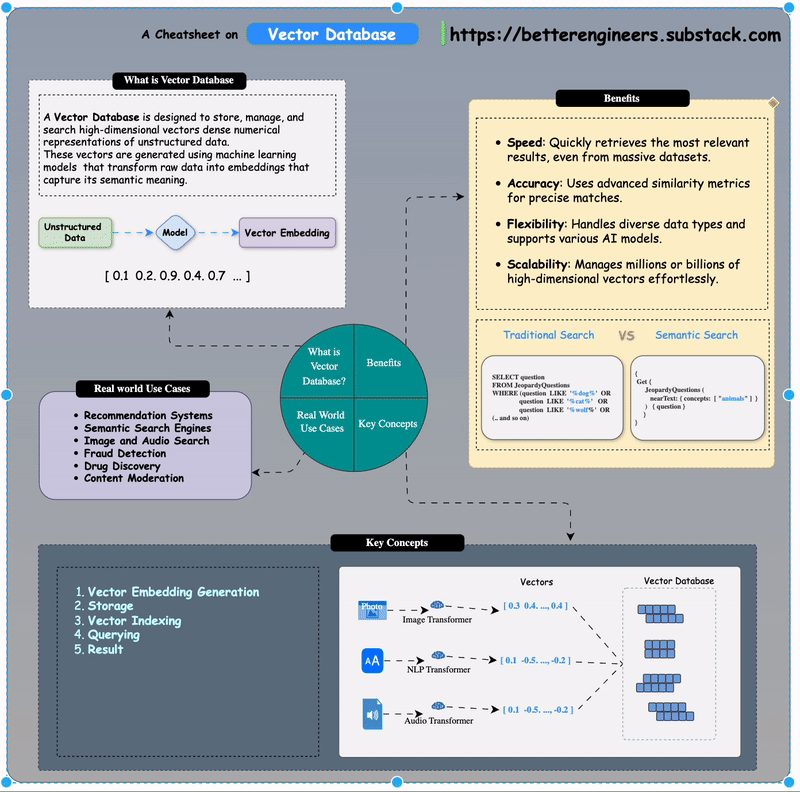
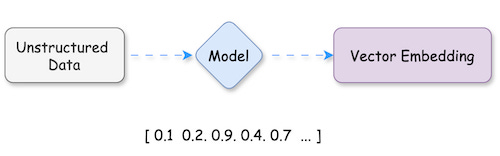
A Vector Database is designed to store, manage, and search high-dimensional vectors dense numerical representations of unstructured data. These vectors are generated using machine learning models that transform raw data into embeddings that capture its semantic meaning.
Think of it as a giant map where every vector is a point in space, and similar data points are closer together. This structure enables efficient similarity searches, even in datasets containing millions of items.
Vector databases facilitate semantic search, which understands user intent rather than relying solely on keyword matching
Understanding Semantic Search

Semantic search utilizes context to enhance search results, as demonstrated by Google's ability to differentiate between "Apple" as a fruit and "Apple" as a company.
The technique involves embedding, which is a numerical representation of text, allowing for better understanding and processing of queries
How Does a Vector Database Work?
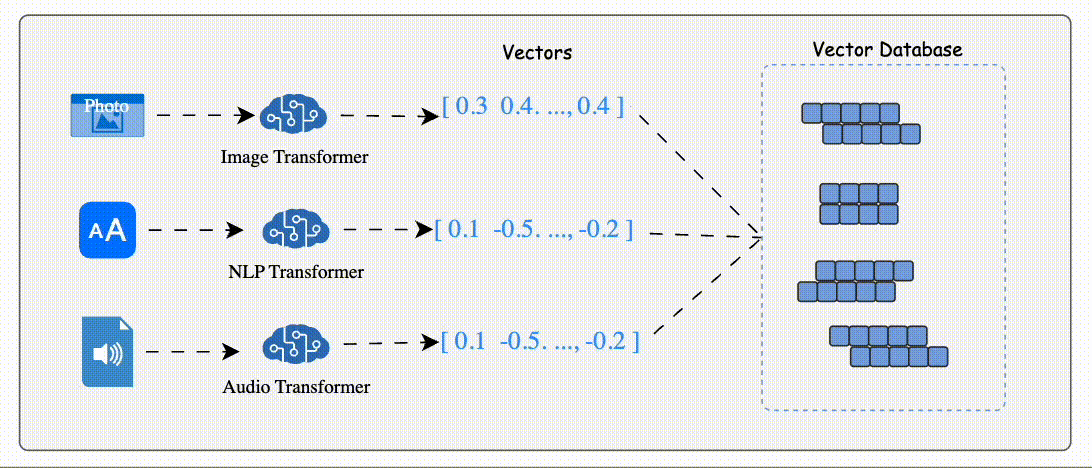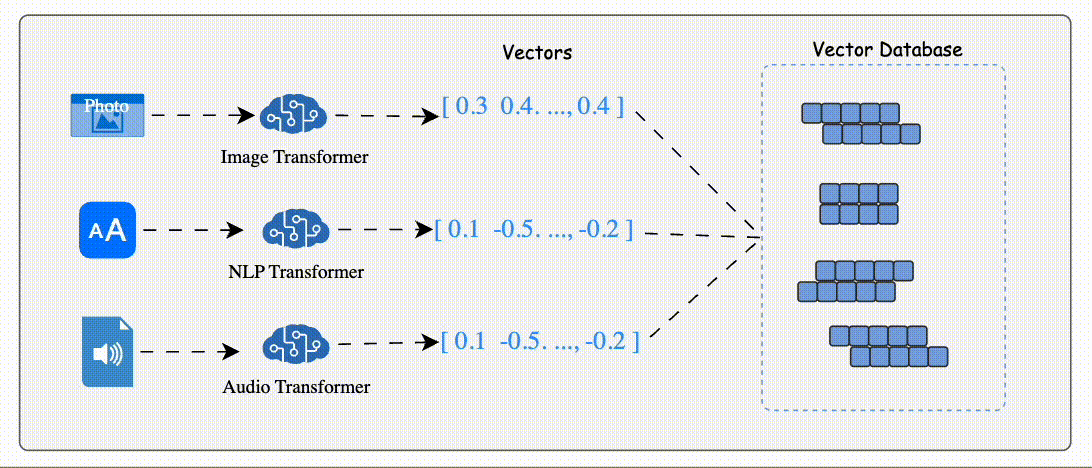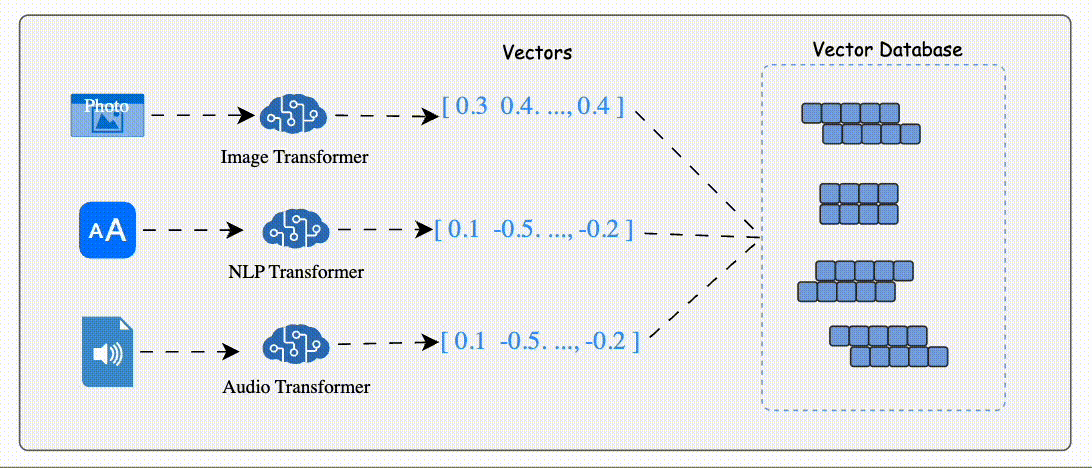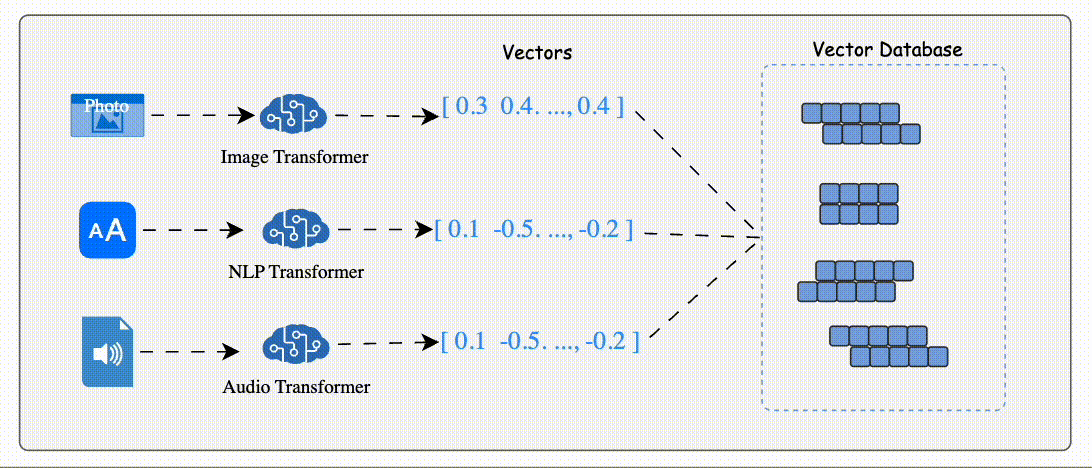
Vector Embedding Generation:
Data (e.g., text, images, audio) is processed by AI models like BERT (for text) or ResNet (for images) to generate vector embeddings.

Vector Embeddi These embeddings are numerical arrays that encapsulate the data's semantic essence.
Storage:
The database stores these embeddings alongside metadata or links to the original content.
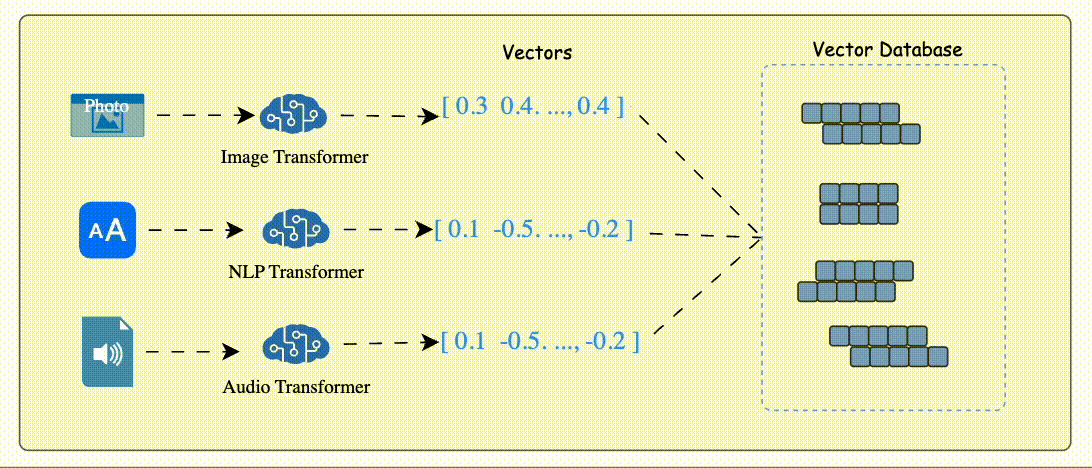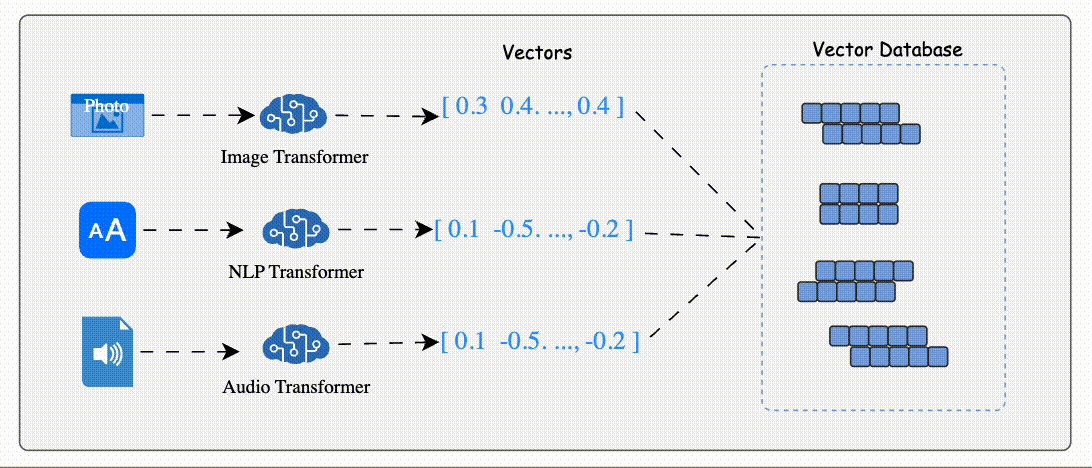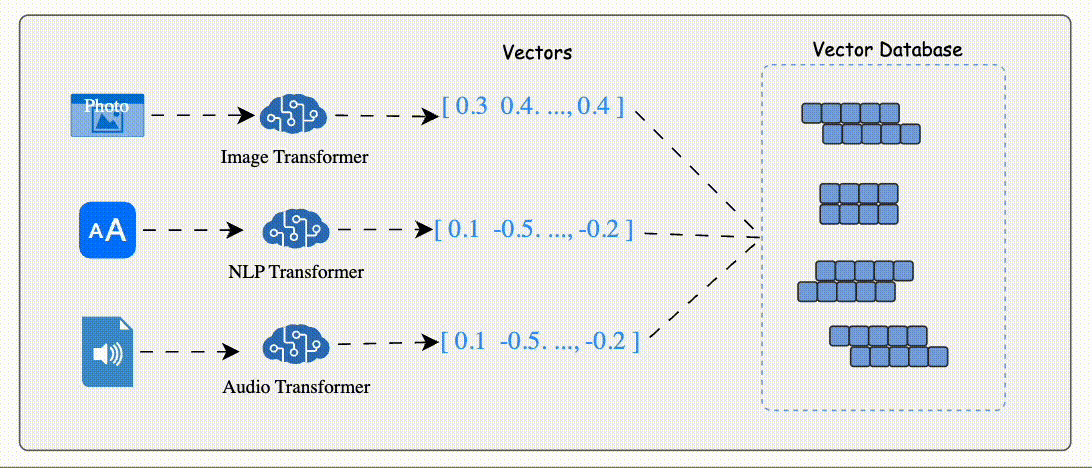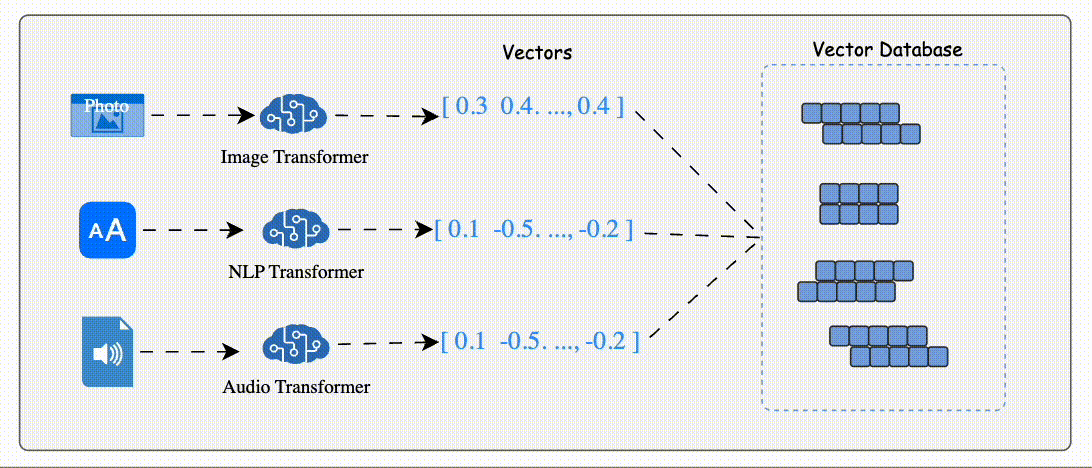
Indexing:
Vector indexing is the process of organizing vector embeddings so that data can be retrieved efficiently.
When you want to find the closest items to a given query vector, the brute force approach would be to use the k-Nearest Neighbors (kNN) algorithm. But calculating the similarity between your query vector and every entry in the vector database requires a lot of computational resources, especially if you have large datasets with millions or even billions of data points. This is because the required calculations increase linearly (O(n)) with the dimensionality and the number of data points.
A more efficient solution to find similar objects is to use an approximate nearest neighbor (ANN) approach. The underlying idea is to pre-calculate the distances between the vector embeddings. Then you can organize and store similar vectors close to each other (e.g., in clusters or a graph), so that you can later find similar objects faster. This process is called vector indexing. Note that the speed gains are traded in for some accuracy because the ANN approach returns only the approximate results.

Vector Indexing Querying:
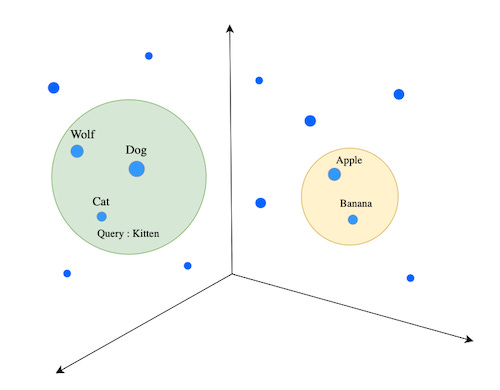
When you query the database for "Kitten", you could start your search by only looking at the closest animals and not waste time calculating the distances between all fruits and other non-animal objects. More specifically, the ANN algorithm can help you to start the search in a region near, e.g., four-legged animals. Then, the algorithm would also prevent you from venturing further from relevant results.
Results:
The database returns the most relevant items based on vector proximity, ranked by similarity scores.
Use Cases of Vector Databases
Have you ever wondered how your favorite streaming platform recommends the perfect movie for you or how search engines understand the nuances of your queries, even when they involve multiple meanings?
Take a look at the following example: how Google can differentiate between searches for "apple taste" and "apple valuation."

Why Use a Vector Database?
Traditional databases struggle with unstructured data and complex queries. A Vector Database is purpose-built for:
Handling Unstructured Data: Works seamlessly with text, images, videos, and audio.
Scalable Performance: Efficiently manages millions or even billions of vectors.
AI Integration: Directly integrates with machine learning workflows for real-time insights.
Real-World Use Cases
1. Recommendation Systems
Example: Netflix or Spotify.
How It Works: User preferences and content are encoded as vectors. The database finds similar vectors to recommend personalized movies or songs.
2. Semantic Search Engines
Example: Google’s search or e-commerce platforms.
How It Works: Queries like "red sneakers under $50" are converted into vectors. The database retrieves results that match the intent, not just the keywords.
3. Image and Audio Search
Example: Reverse image search or Shazam for music.
How It Works: Upload a photo or audio file, and the database identifies similar images or tracks using vector embeddings.
4. Fraud Detection
Example: Identifying anomalous transactions in banking.
How It Works: Transaction patterns are represented as vectors, and outliers are flagged as suspicious activities.
5. Drug Discovery
Example: Identifying molecules similar to a target drug.
How It Works: Molecular structures are transformed into vectors for similarity search, speeding up research and innovation.
6. Content Moderation
Example: Social media platforms filtering inappropriate content.
How It Works: Vectors of flagged content are compared with new uploads to detect violations.
Examples of Vector Databases
Milvus:
Open-source, scalable, and widely used in AI applications like image recognition and semantic search.

Pinecone:
A managed vector database service that emphasizes ease of use and integration with ML workflows.
Weaviate:
Open-source and highly customizable with rich metadata handling capabilities.
FAISS (Facebook AI Similarity Search):
A library for efficient similarity search, often embedded in larger systems.
Qdrant:
User-friendly, open-source database designed for high-dimensional data.

Benefits of Using Vector Databases

Speed: Quickly retrieves the most relevant results, even from massive datasets.
Accuracy: Uses advanced similarity metrics for precise matches.
Flexibility: Handles diverse data types and supports various AI models.
Scalability: Manages millions or billions of high-dimensional vectors effortlessly.
How to Build an AI-Powered Search with a Vector Database
Data Preparation:
Convert your data (e.g., text, images) into vector embeddings using pre-trained models like BERT, ResNet, or OpenAI's embeddings.
Vector Storage:
Store these embeddings in a vector database along with relevant metadata.
Querying:
When a user submits a query, convert it to a vector using the same model.
Similarity Search:
Perform a vector search to find the closest matches.
Result Display:
Present the most relevant results to the user.
The Future of Vector Databases
As AI continues to evolve, Vector Databases will become integral to applications that rely on unstructured data. They bridge the gap between raw data and actionable insights, enabling innovations in personalization, automation, and search.
Whether you're building a cutting-edge recommendation engine or enhancing your enterprise search, a Vector Database is the foundation you need to unlock the full potential of your AI systems.
See you next week with more resources to help you grow in your tech career!
- Better Engineeirng
P.S. Know someone who'd benefit from these resources? Share this post and spread the knowledge!