

In distributed systems, databases can be categorized based on various criteria such as data distribution, consistency model, replication strategy, and more. Here are some common types of databases used in distributed systems:
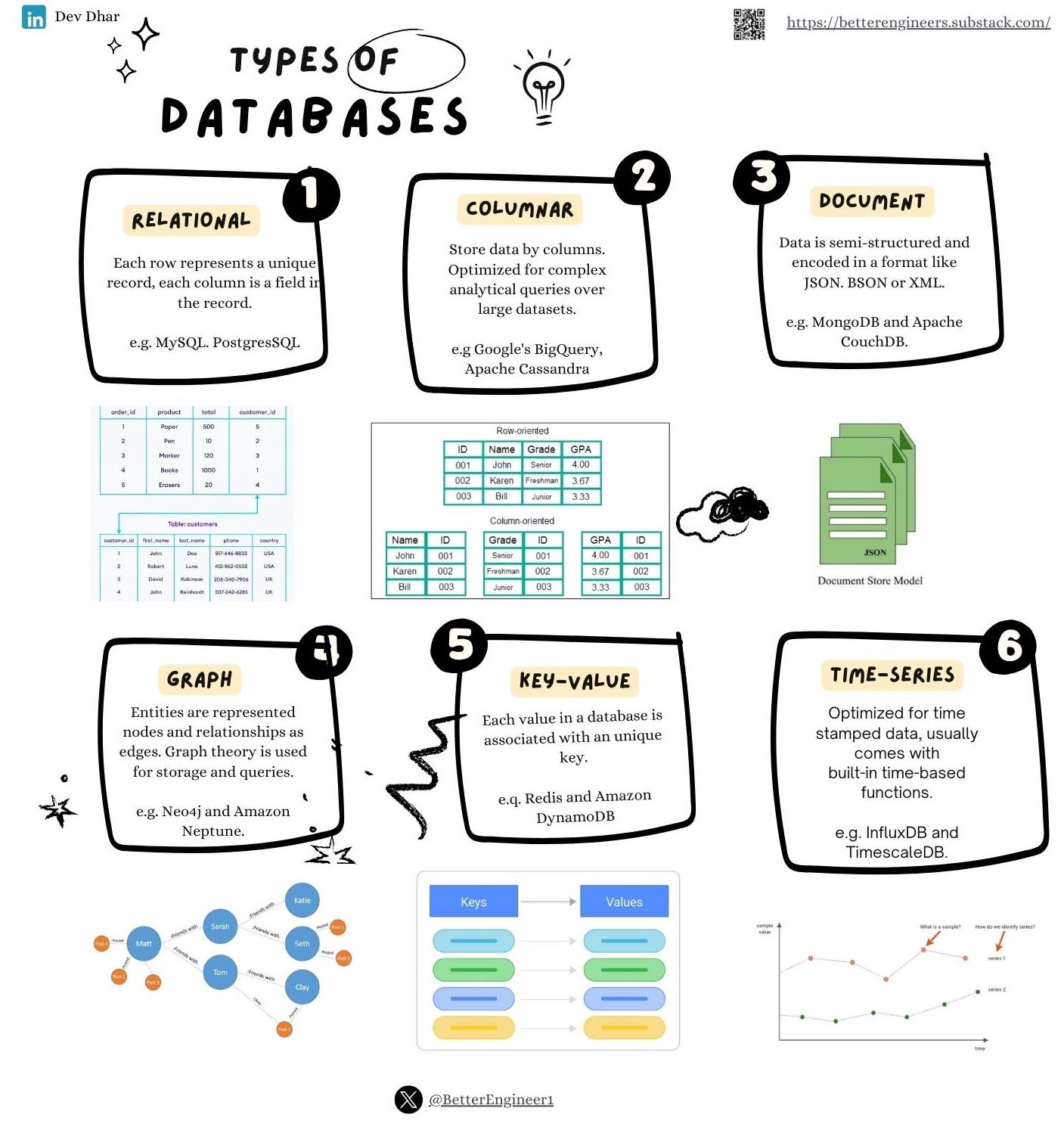
1. Relational Databases (RDBMS)
A relational database management system (RDBMS) is a program used to create, update, and manage relational databases. Some of the most well-known RDBMSs include MySQL, PostgreSQL, MariaDB, Microsoft SQL Server, and Oracle Database.
Benefits of relational databases :
Flexibility
It’s easy to add, update, or delete tables, relationships, and make other changes to data whenever you need without changing the overall database structure or impacting existing applications.
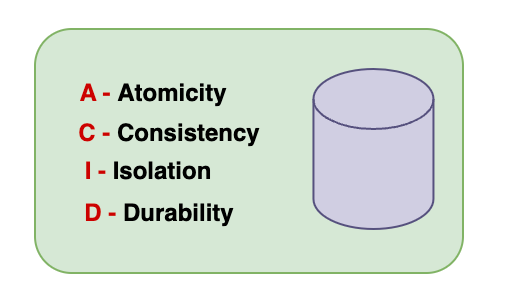
ACID compliance
Relational databases support ACID (Atomicity, Consistency, Isolation, Durability) performance to ensure data validity regardless of errors, failures, or other potential mishaps.
Database normalization
Relational databases employ a design technique known as normalization that reduces data redundancy and improves data integrity.
Built-in security
Role-based security ensures data access is limited to specific users.
Collaboration
Multiple people can operate and access data simultaneously. Built-in locking prevents simultaneous access to data when it’s being updated.
2. NoSQL Databases
The term NoSQL, short for “not only SQL,” refers to non-relational databases that store data in a non-tabular format, rather than in rule-based, relational tables like relational databases do. NoSQL databases use a flexible schema model that supports a wide variety of unstructured data such as documents, key-value, wide columns, and graphs.
Organizations choose NoSQL databases for their flexibility, high performance, horizontal scalability, and ease of development.
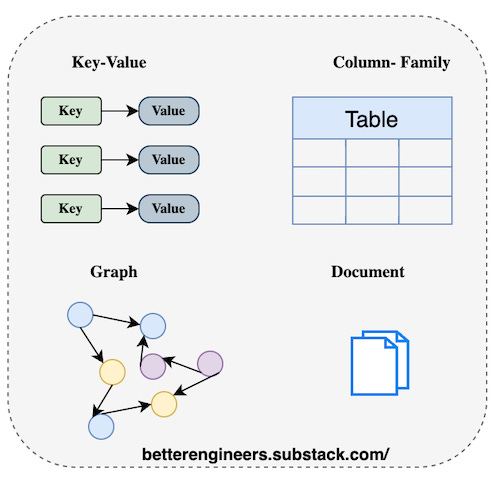
Key-Value Stores
Store data as a collection of key-value pairs. -
Redis :
Often used for caching but can also serve as a primary database.
Riak KV :
Designed for high availability and fault tolerance.
Document Stores :
Store, retrieve, and manage document-oriented information.
MongoDB
Popular for its flexibility and scalability.
Couchbase
Offers JSON document storage with SQL-like querying.
Wide Column Stores
Store data in tables, rows, and dynamic columns.
Apache Cassandra
Known for its scalability and fault-tolerance.
HBase
Part of the Hadoop ecosystem, designed for random, real-time read/write access to Big Data.
Graph Databases
Designed for managing relationships between data points.
Neo4j
Ideal for complex queries involving relationships. -
Amazon Neptune
A fully managed graph database service.
3. NewSQL Databases
NewSQL databases try to address the limitations of the existing databases. They’re engineered as a relational database with a distributed and fault-tolerant architecture.

They aim to provide solutions by providing a database with the following features:
Scalability and ACID compliance: Designed to scale horizontally, the NewSQL databases handle large amounts of data by distributing them across nodes/clusters. Additionally, they maintain strict ACID compliance resulting in a system that is highly available and with strong transactional integrity.
Performance optimization: Various techniques, such as in-memory processing, indexing, and caching, are implemented to provide low-latency data access and high performance.
Distributed architecture: Multiple nodes are used to replicate data so that there is no single point of failure. Consequently, it ensures high availability and fault tolerance
SQL compatibility: NewSQL systems are compatible with SQL query language thus avoiding re-learning and migration overheads.
Example of NewSQL Databases:
An open-source distributed database designed to survive different types of failures while still maintaining ACID compliance. It uses distributed architecture and provides strong failover capabilities along with automatic data replication.
NuoDB: It uses a patented “elastically scalable databases” architecture to provide NoSQL benefits while retaining ACID compliance.
VoltDB: An in-memory database that uses a shared-nothing architecture designed for high-velocity data ingestion.
4. Time-Series Databases
Time series data is the collection of data that is queried and indexed based on time-period.
CUSTOMER_TRANSACTIONS
2022-04-14 11:25:25 Login attempt
2022-04-14 11:25:26 Login success
2022-04-14 11:26:03 Browse category accessories
2022-04-14 11:27:04 Added 2 items in cart
2022-04-14 11:28:02 Browse category electronicsRelational and non-relational databases have timestamp data types to store time-related data. Time series databases are specifically designed for time series data management.

Example for Time-Series databases :
InfluxDB : Designed for IoT and monitoring data.
TimescaleDB: A time-series database built on PostgreSQL.
5. Search Databases
Specialized for full-text search capabilities.
Elasticsearch : Often used for log analytics, full-text search, and business analytics.
6. In-Memory Databases
Store data primarily in RAM for faster access. -
Redis : While primarily a key-value store, it's often used as an in-memory database.
SAP HANA : Combines in-memory computing with columnar storage.
7. Hybrid Transactional/Analytical Processing (HTAP) Databases
Designed to handle both OLTP (Online Transaction Processing) and OLAP (Online Analytical Processing) workloads efficiently.
SAP HANA also falls into this category due to its capabilities.
8. Blockchain Databases
Distributed ledger databases where data is stored in blocks and secured through cryptography. -
Hyperledger Fabric: Designed for enterprise use with a modular architecture.
Database Cheat Sheet
Keep reading with a 7-day free trial
Subscribe to Better Engineers to keep reading this post and get 7 days of free access to the full post archives.