The Algorithm That Keeps Your Distributed System From Falling Apart
How consistent hashing powers DynamoDB, Cassandra, and Redis Cluster — and why every senior engineer needs to understand it

You’re running a caching cluster with 4 servers. Traffic grows and you add a 5th. The next morning your database is on fire — 100% cache miss rate, requests piling up, on-call paging at 3am.
What happened?
You used the wrong hashing strategy. And this exact scenario has taken down production systems at companies far larger than yours.
Today we’re going deep on consistent hashing — the algorithm that makes distributed systems actually work when nodes come and go.
The Problem: Naïve Hashing Is a Ticking Time Bomb
The obvious way to distribute data across N servers is simple modular arithmetic:
server = hash(key) % N
It works great. Until you change N.
Add one server (N becomes 5), and suddenly almost every key maps to a different server. Your entire cache is invalid. Every request hits the database. You’ve just caused a thundering herd.
Here’s the math that makes this painful:
4 servers → 5 servers
Keys that stay on the same server: roughly 1/5 = 20%
Keys that move: ~80%
This is why you can’t just scale a cache cluster horizontally without careful thought. Every resize is a potential outage.
The Insight Behind Consistent Hashing
Consistent hashing was introduced in a 1997 paper by Karger et al. at MIT. The core insight is elegant:
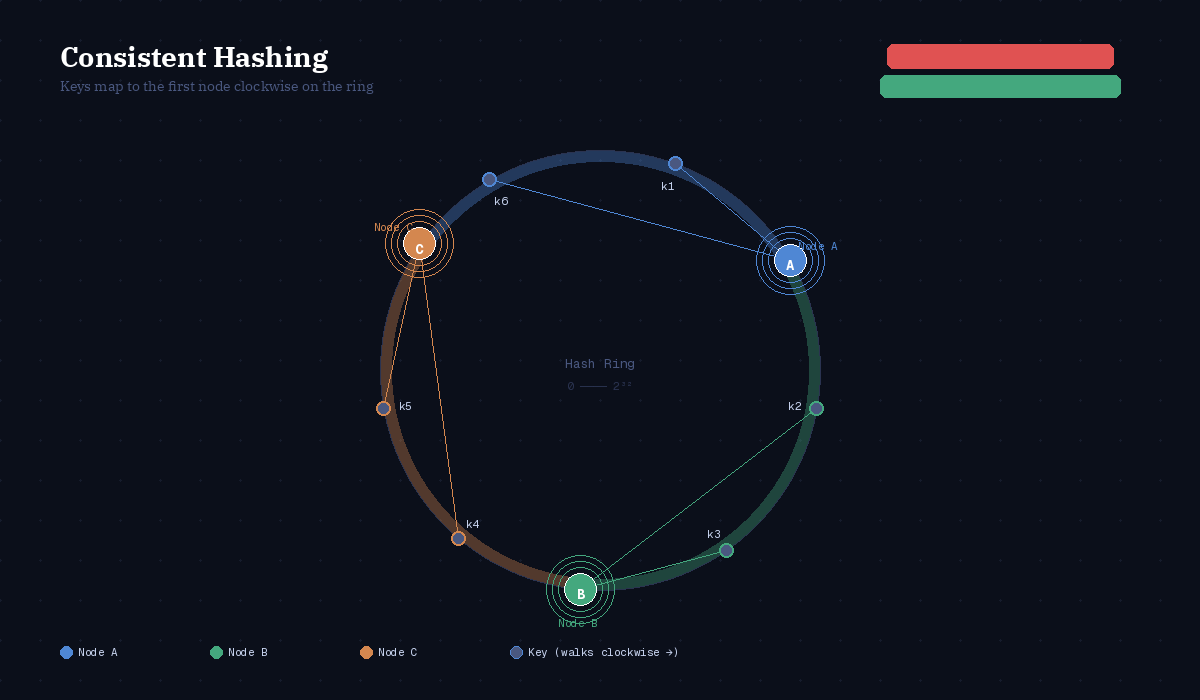
Map both servers and keys onto the same circular hash space — then assign each key to the first server clockwise from it.
Instead of hash(key) % N, you do:
Hash every server onto a ring from 0 to 2³²
Hash every key onto the same ring
Walk clockwise from the key’s position — the first server you hit owns that key
The ring wraps around: the key at position 359° is owned by the server at 2°.
Visualizing the Ring
Subscribe for Interactive PlayGround to understand Consistent Hashing .