

In a microservices architecture, data is typically decentralized, with each service owning its own data store. This independence allows services to scale and operate autonomously, but it also introduces challenges when querying data across the system. Unlike in a monolithic architecture, where complex queries can be handled by a single database, a distributed architecture must adopt different strategies to ensure data is efficiently accessible across multiple services.
One common solution to these challenges is storing copies of data, a technique that can enhance query performance, improve system resilience, and reduce the reliance on real-time inter-service communication.
Cheatsheet on CQRS :
The Challenges of Queries in a Distributed System
Data Aggregation Across Services:
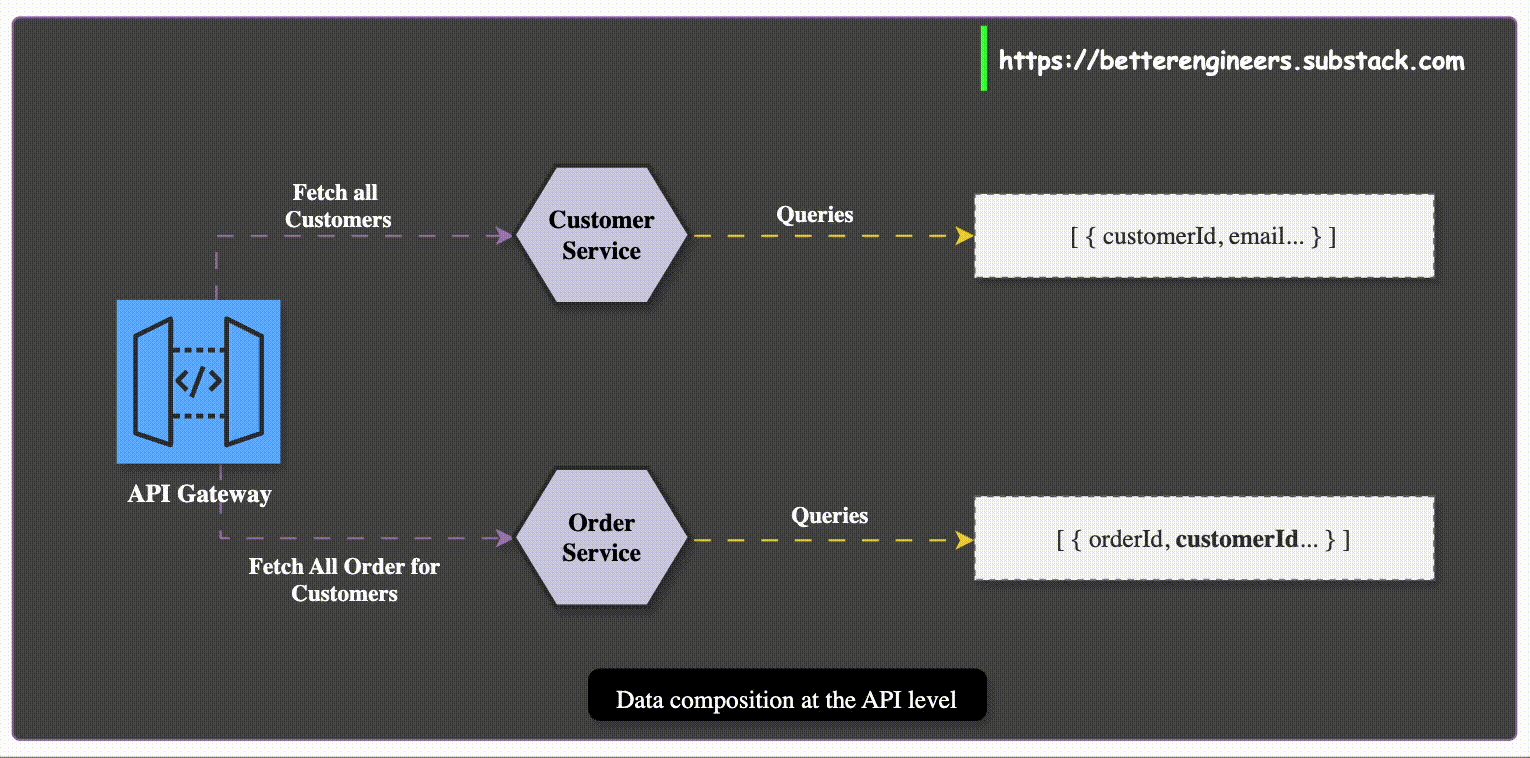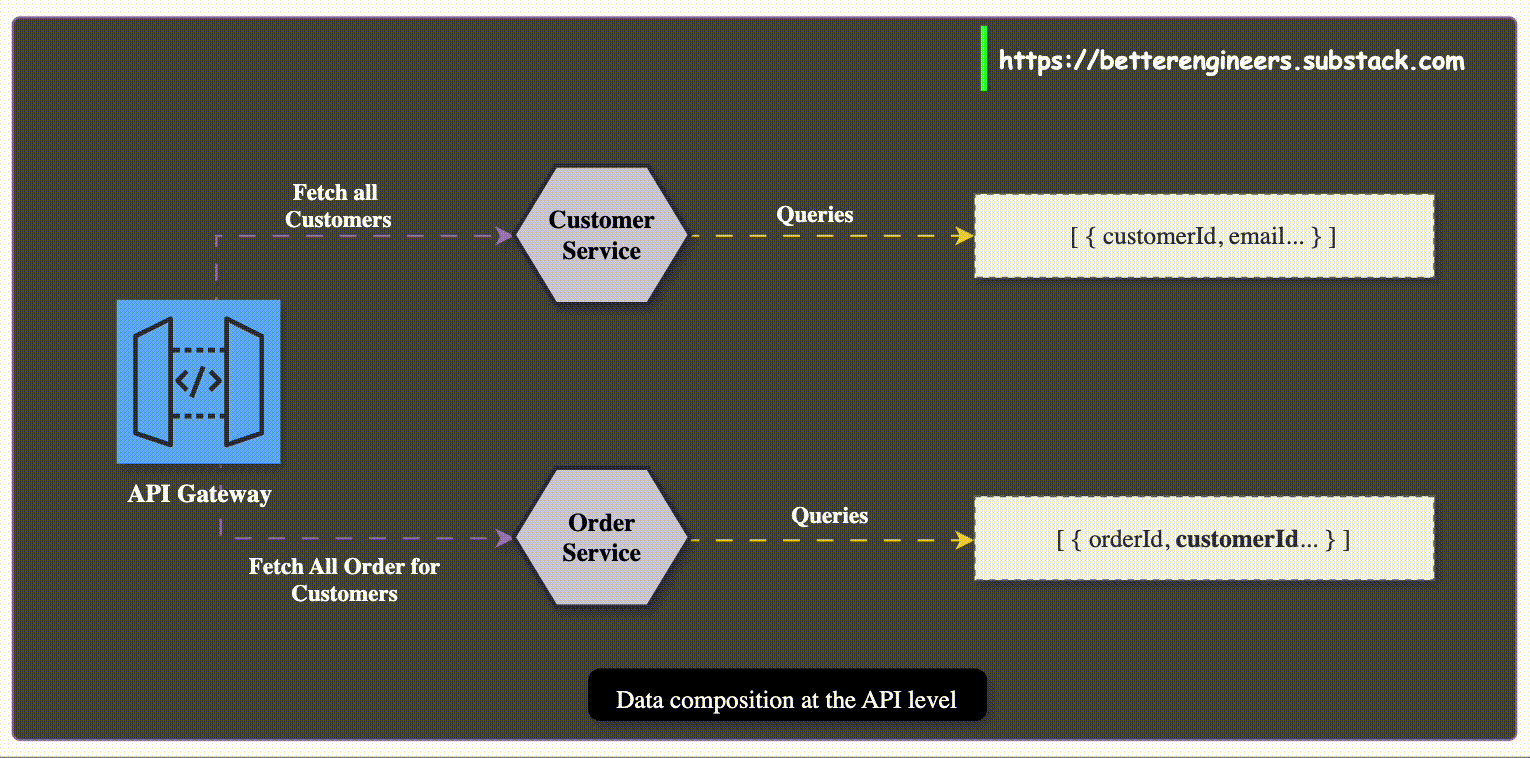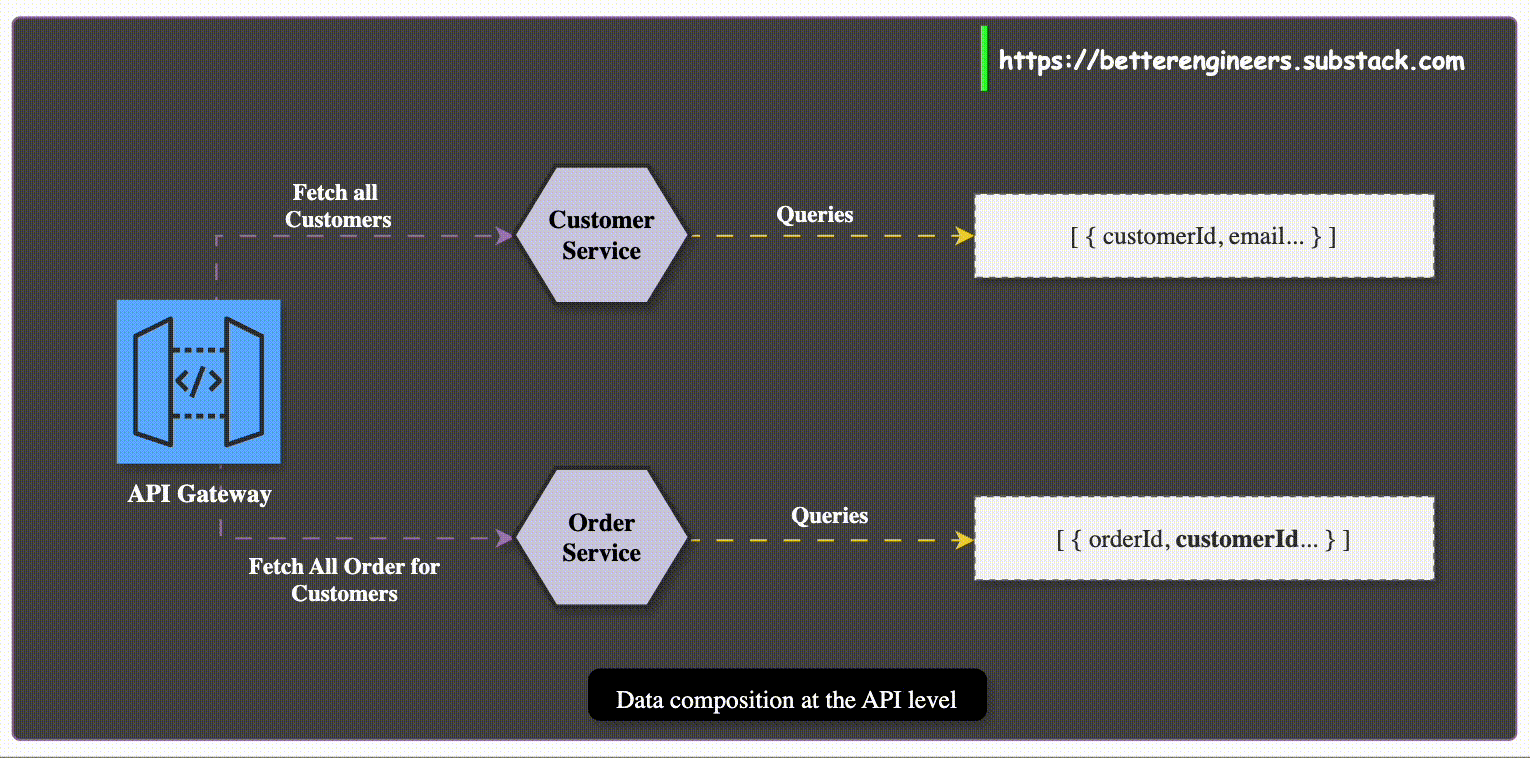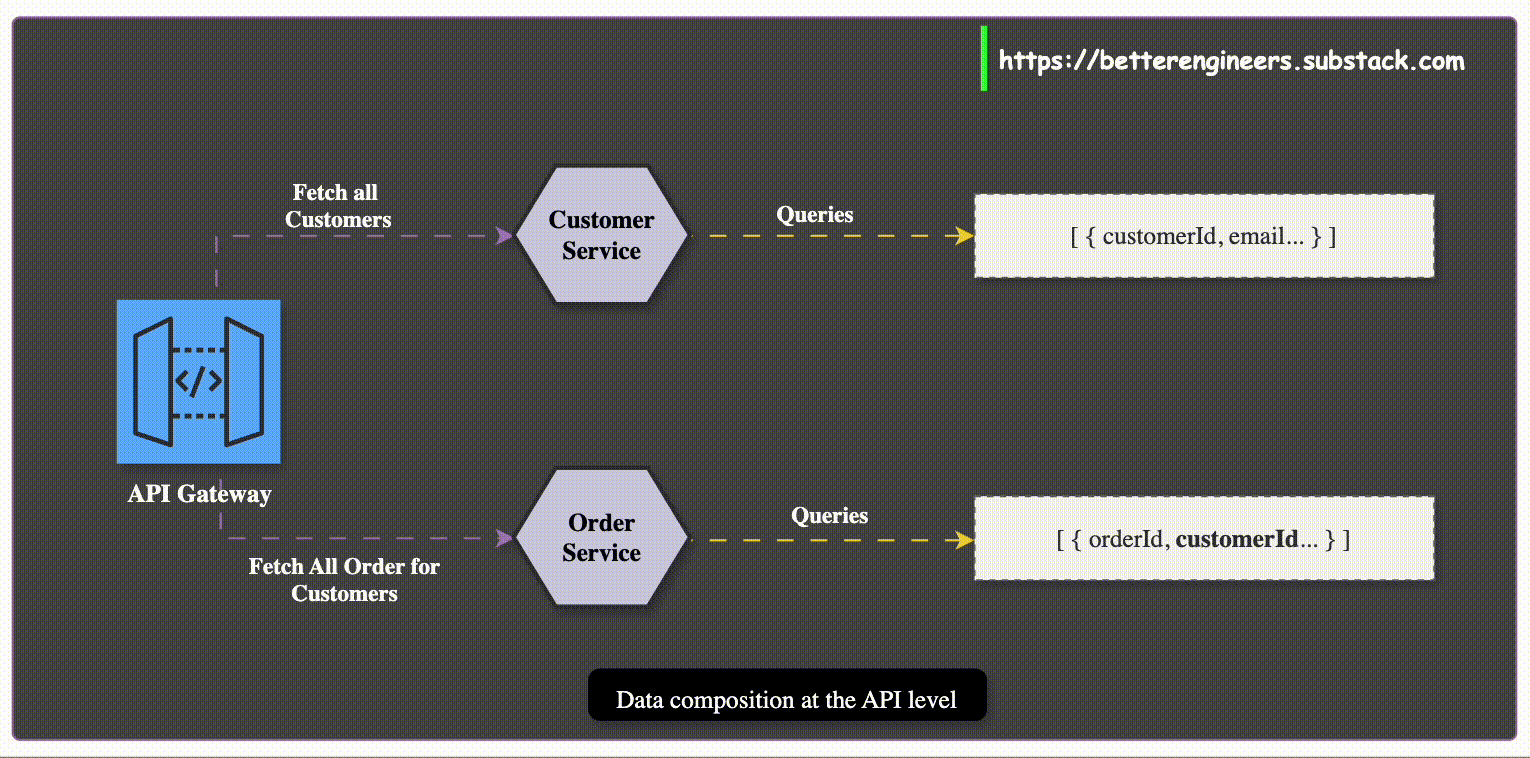
In a monolithic setup, you can easily join data from different tables to create complex queries. However, in a microservices architecture, data is distributed across multiple services, each with its own database. For example, Customer data might reside in the Customer Service, while Order data is managed by the Order Service.
To retrieve combined data, like displaying a customer’s orders, an application must make separate calls to the Customer and Order services, then aggregate the results. This increases network latency and can become a performance bottleneck.
Network Overhead and the N+1 Query Problem:
When querying data across services, the number of network requests can grow significantly, leading to what is known as the N+1 query problem. For example, retrieving a list of customers and then fetching orders for each customer can result in N+1 network requests, where N is the number of customers. This increases latency and resource consumption.
Additionally, the availability of one service can impact the query results. If a required service is down, the query may fail or produce incomplete data.
Consistency vs. Availability:
Distributed systems often favor availability over strict consistency, leading to the concept of eventual consistency. This means that while data will become consistent over time, there might be a delay in reflecting recent changes across all services. Handling this trade-off is crucial when designing data access patterns.
Storing Copies of Data: A Solution for Efficient Queries
To address these challenges, storing copies of data can significantly enhance the querying capabilities of a distributed system. Here’s how it works and why it’s beneficial:
How Data Copies Work:
Event-Driven Data Synchronization: When a service, such as the Order Service, creates or updates data, it publishes events like OrderCreated or OrderUpdated. Services that need order data, like the Customer Service, can subscribe to these events and store a local copy of the relevant order details.
This way, when the Customer Service needs to display a customer's orders, it can access the locally stored data without having to make additional calls to the Order Service.
Reducing Network Dependency:
By maintaining local copies, services can avoid making frequent calls to each other for data, reducing the network overhead and improving the performance of queries. This is particularly beneficial in read-heavy applications, where data needs to be fetched frequently but does not change often.
For example, a dashboard service that displays a list of recent orders can cache order data locally, allowing it to present the information without needing to interact with the Order Service for every request.
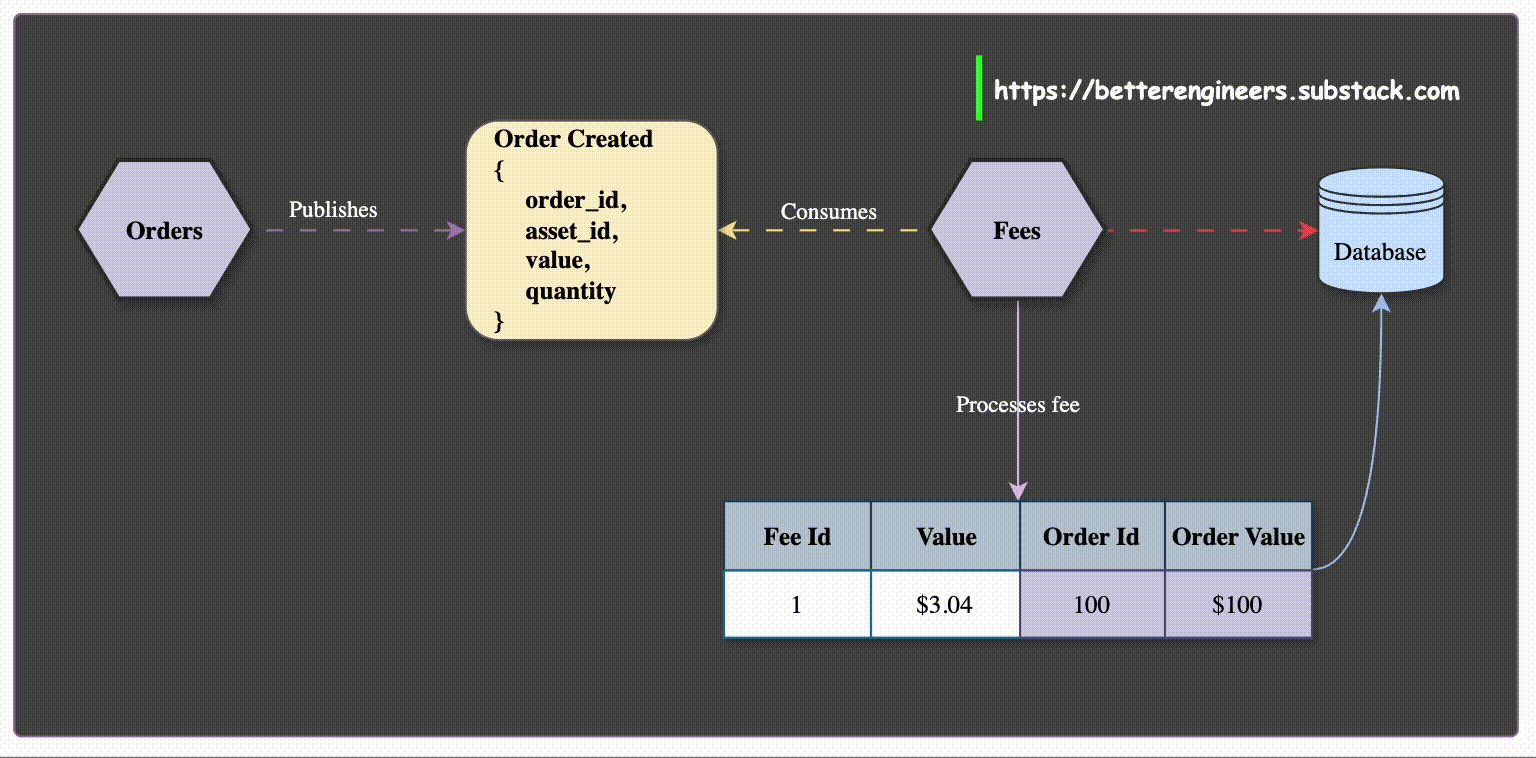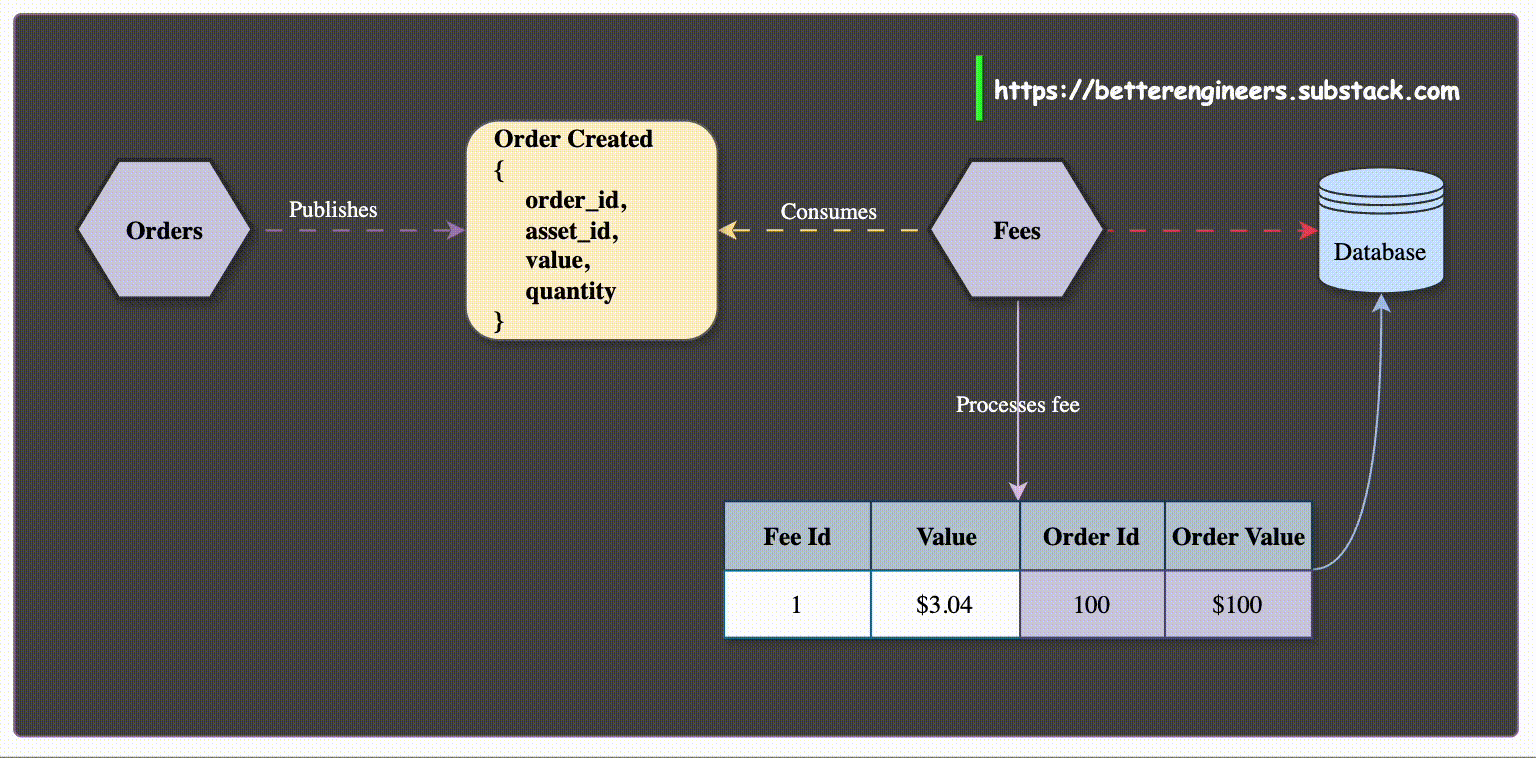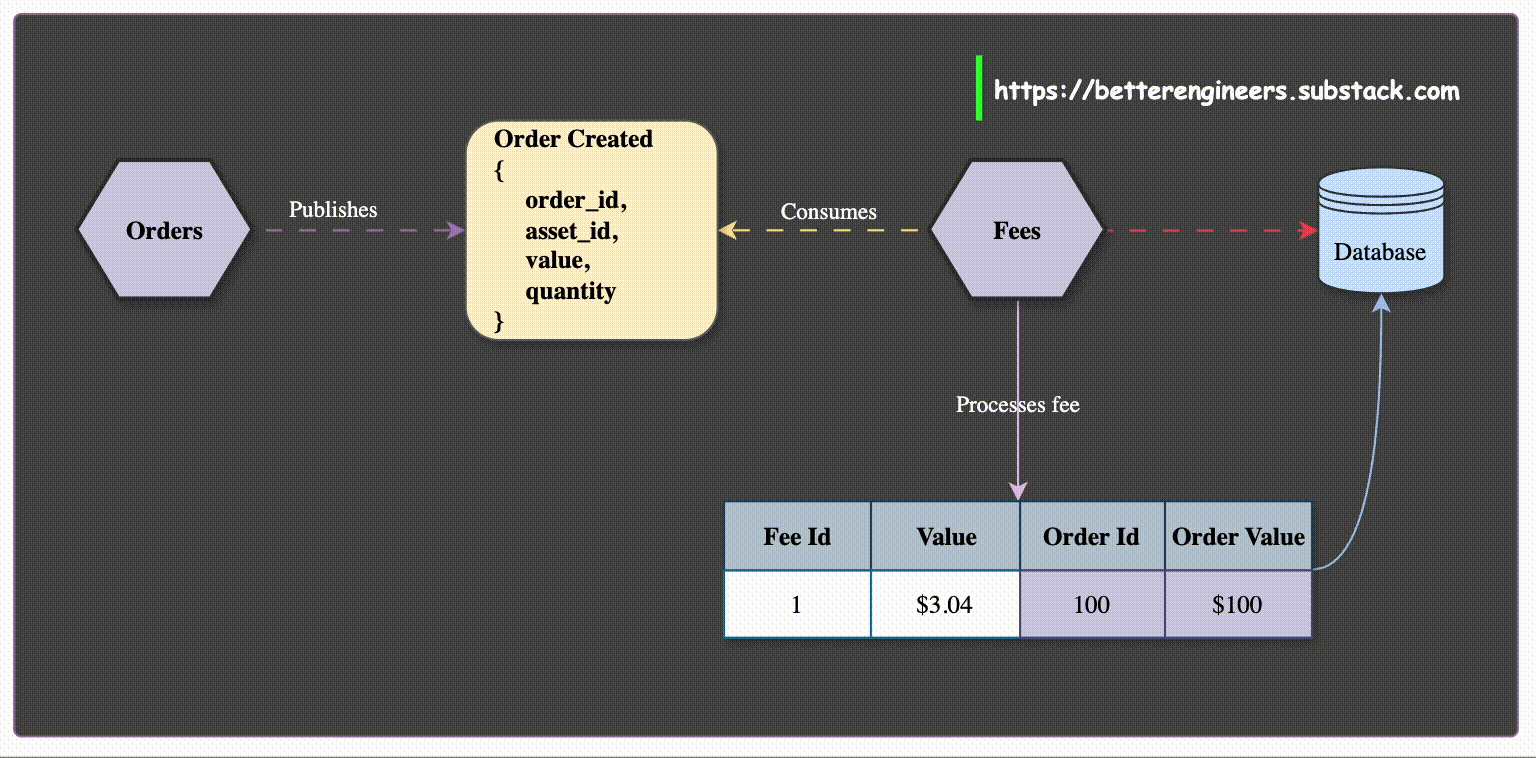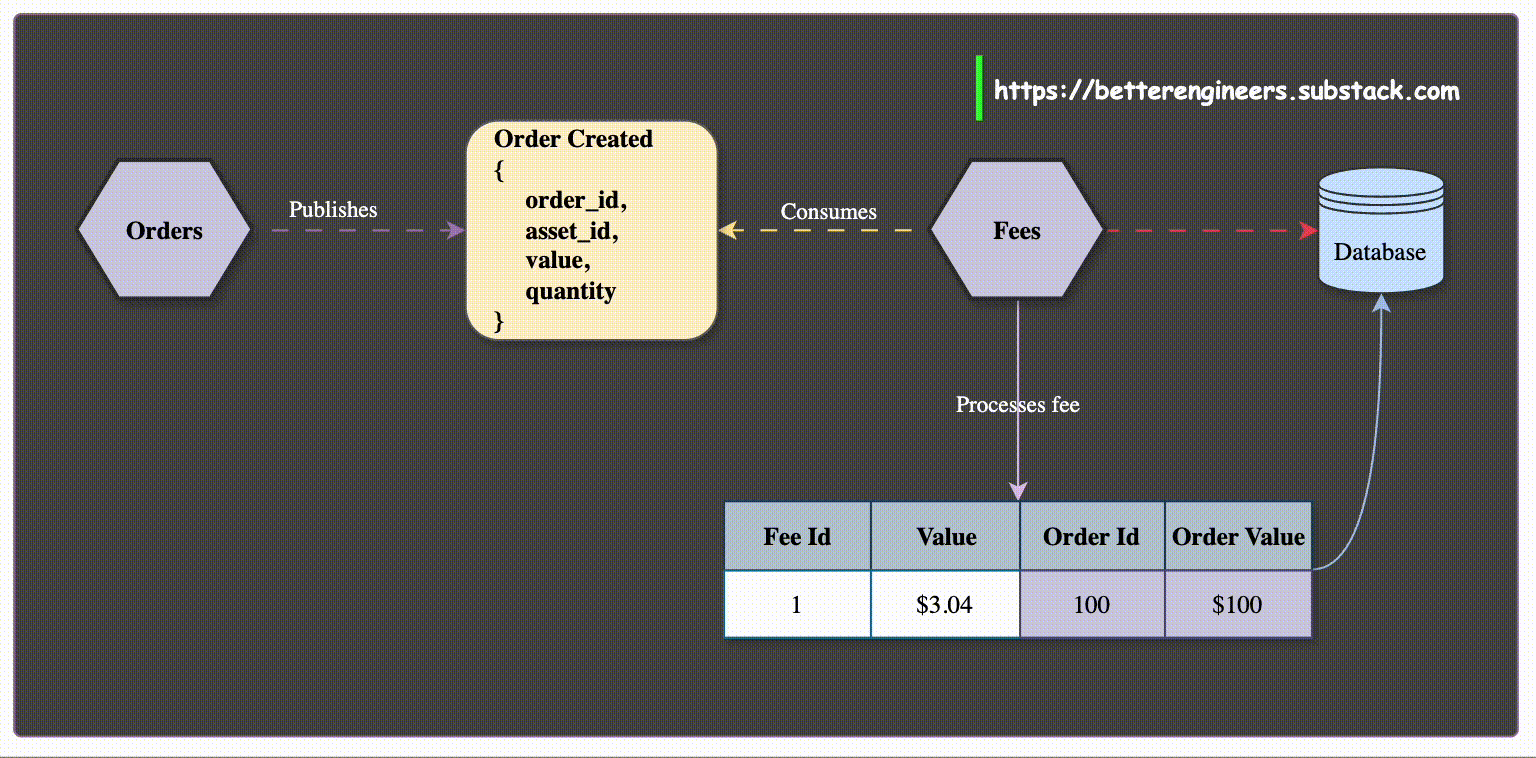
Enhanced Resilience and Availability:
Local copies of data help services continue operating smoothly even if other services become temporarily unavailable. For example, if the Order
This approach contributes to the overall resilience of the system, as it minimizes the impact of service failures on the user experience.
Challenges of Storing Copies of Data
While storing copies offers many advantages, it also introduces new complexities:
Eventual Consistency:
The asynchronous nature of updating data copies means that there can be a lag between the time data changes in the source service and when the changes are reflected in the copied data. This means that services need to be designed to handle slightly outdated information until the next synchronization.
For example, if a user updates their order, the updated details might not immediately reflect in the Customer Service's local copy due to the time taken to process the event.
Increased Storage Requirements:
Each service that stores a copy of data increases the overall storage footprint of the system. This can add costs, especially if multiple services require large data sets.
Additionally, managing schema changes across services becomes more complex. If a data structure changes in the Order Service, every service storing a copy must adapt to the change, potentially leading to tight coupling between services.
Managing Data Synchronization:
As services become dependent on event-driven updates, it’s crucial to ensure that these updates are processed correctly and in the right order. This requires reliable messaging systems and handling scenarios like dropped events or delayed message processing.
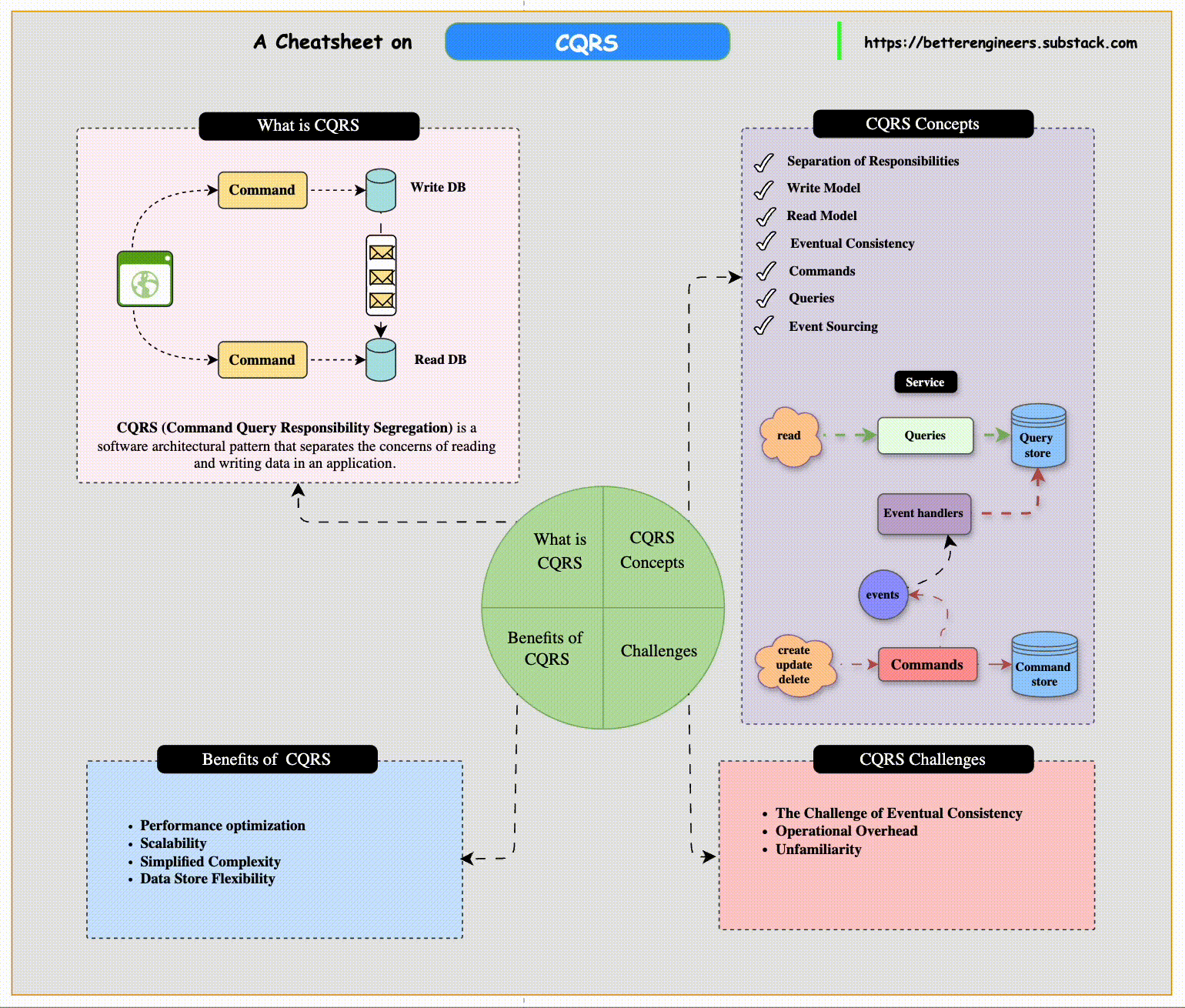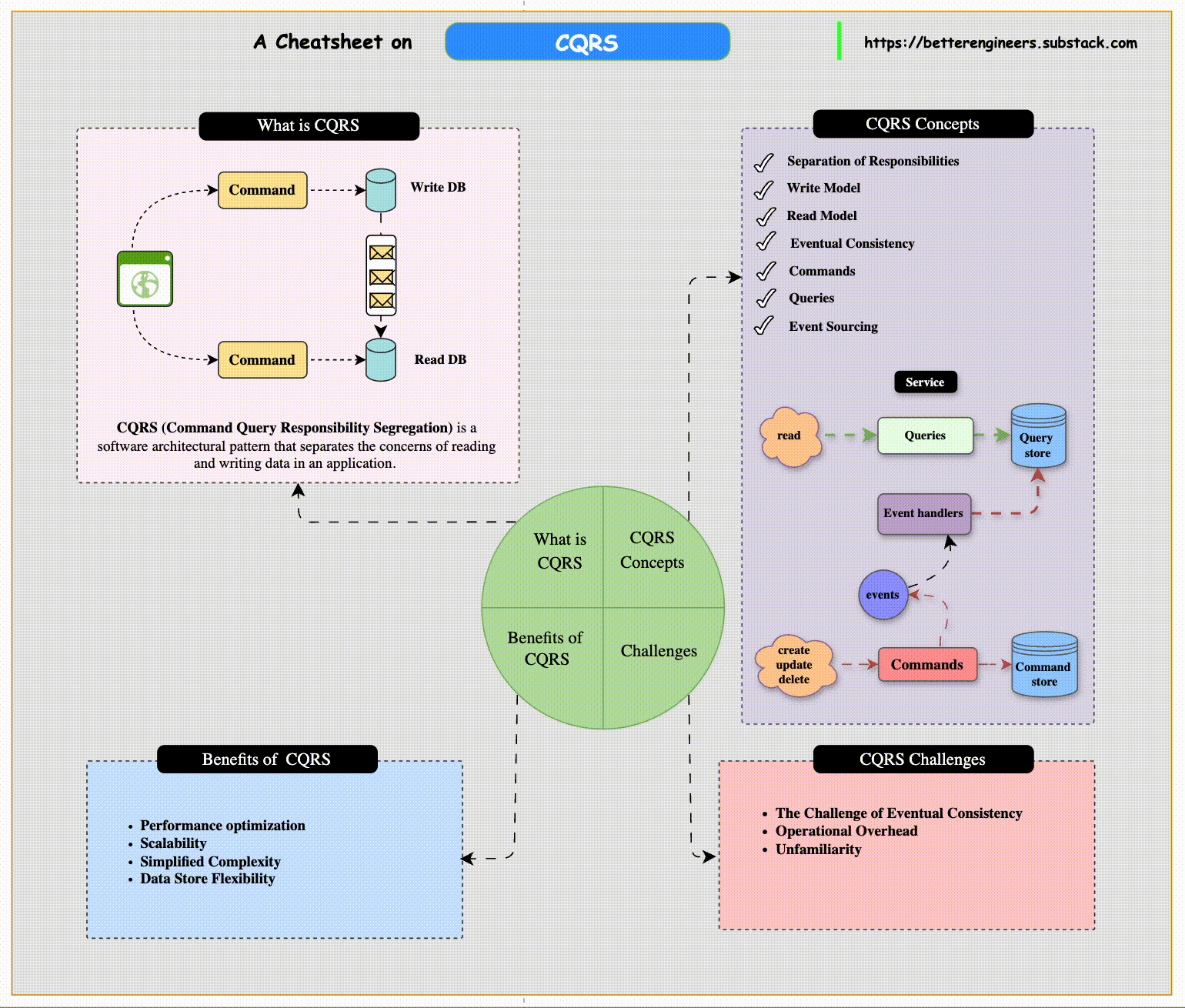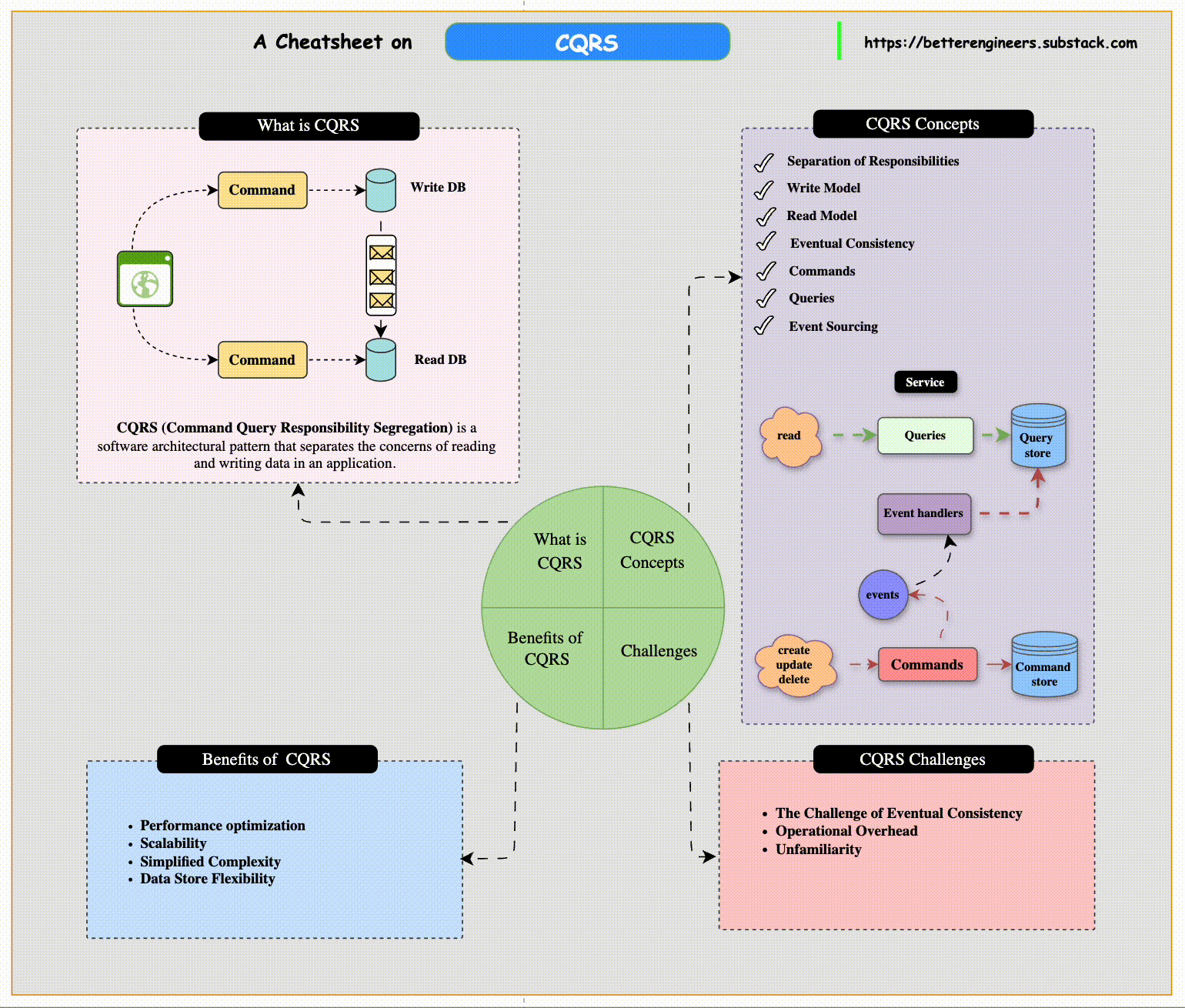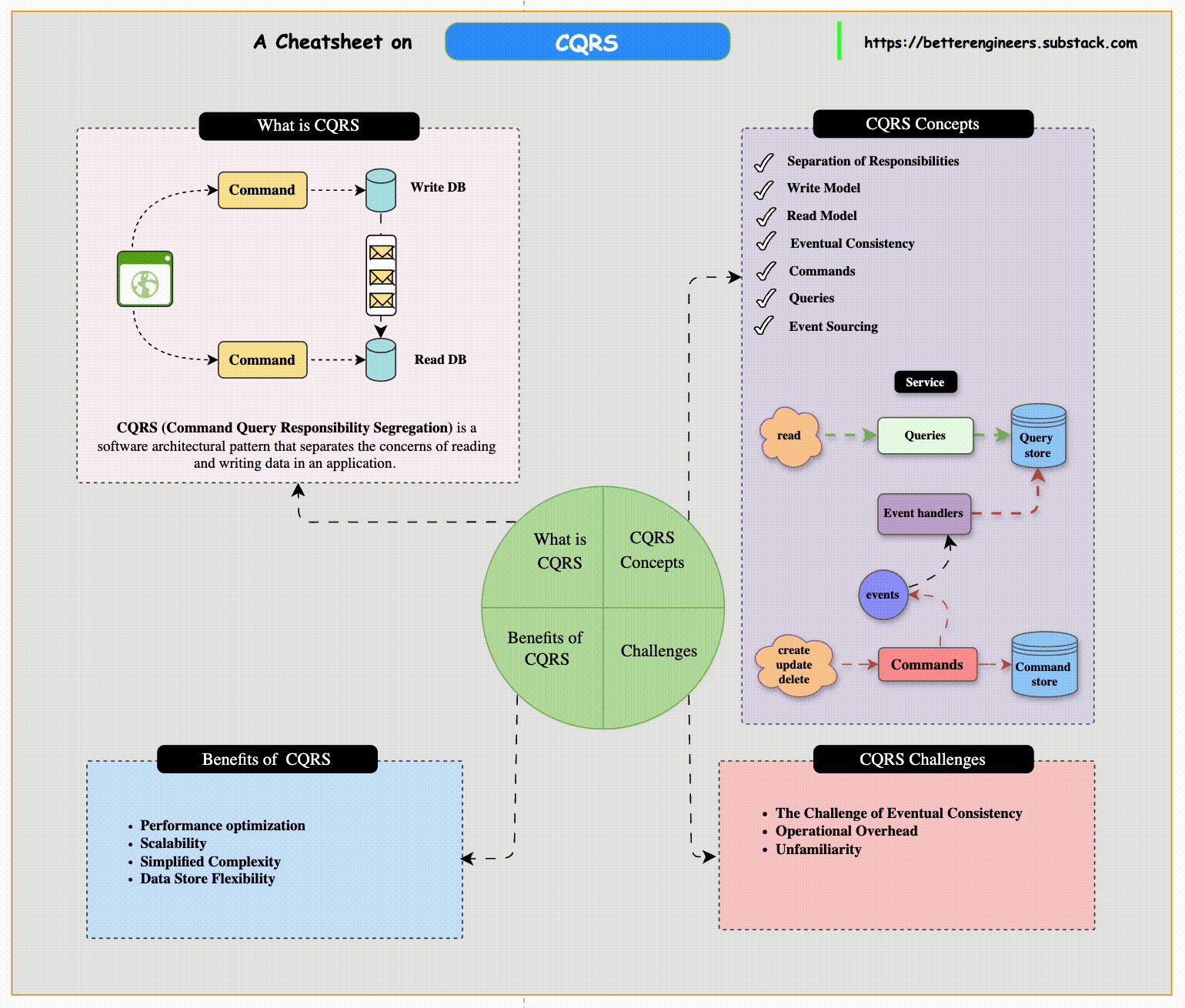
Separating Queries and Commands in CQRS
The Command Query Responsibility Segregation (CQRS) pattern is particularly useful in systems where the nature of reading data (queries) is significantly different from writing data (commands). This pattern explicitly separates the read and write operations within an application, allowing each side to be optimized for its specific purpose.
Why Separate Reads and Writes?
In many systems, writes (or commands) and reads (or queries) have inherently different characteristics:
Commands (writes) are operations that change the state of the system. These typically involve creating, updating, or deleting highly normalized data entities to ensure data integrity and consistency.
Queries (reads) are used to retrieve data. Often, queries need to access denormalized data across multiple sources to provide a comprehensive view. For example, a query might need data from several tables or services to produce a summary view or report.
The CQRS pattern helps to manage these differences by partitioning commands and queries, which allows each to be handled in a way that best suits its nature.
CQRS Architecture Overview
The CQRS pattern involves creating distinct models for handling reads and writes, which can include separate data stores for each side. Here’s how it works:
Command Side:
The command side of an application is responsible for handling updates to the system. It manages operations like creating new entries, updating existing records, or deleting data.
Commands emit events when changes occur. These events represent facts about what happened, such as OrderCreated or CustomerUpdated.
Events can be processed in-band (within the same service) or sent to an event bus like RabbitMQ or Kafka for asynchronous processing.
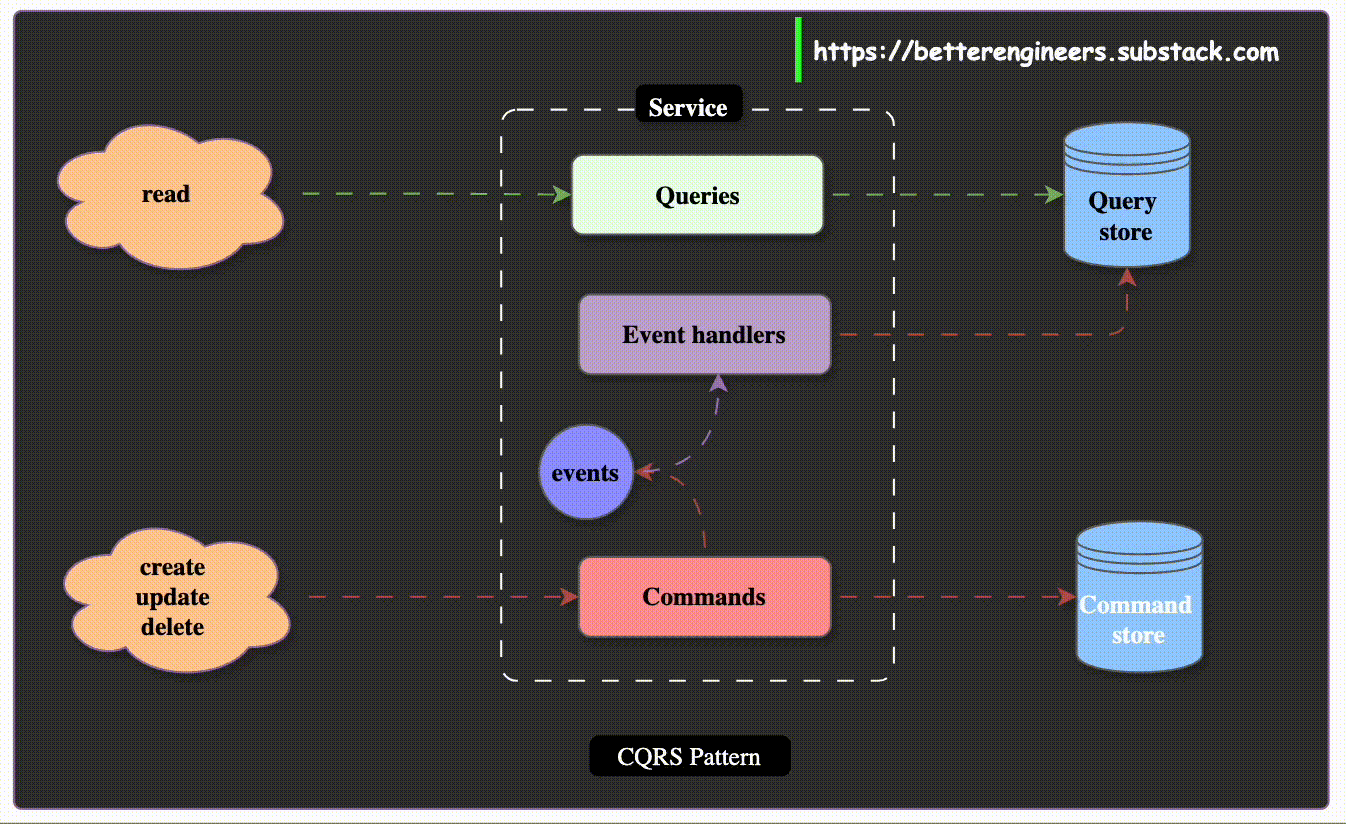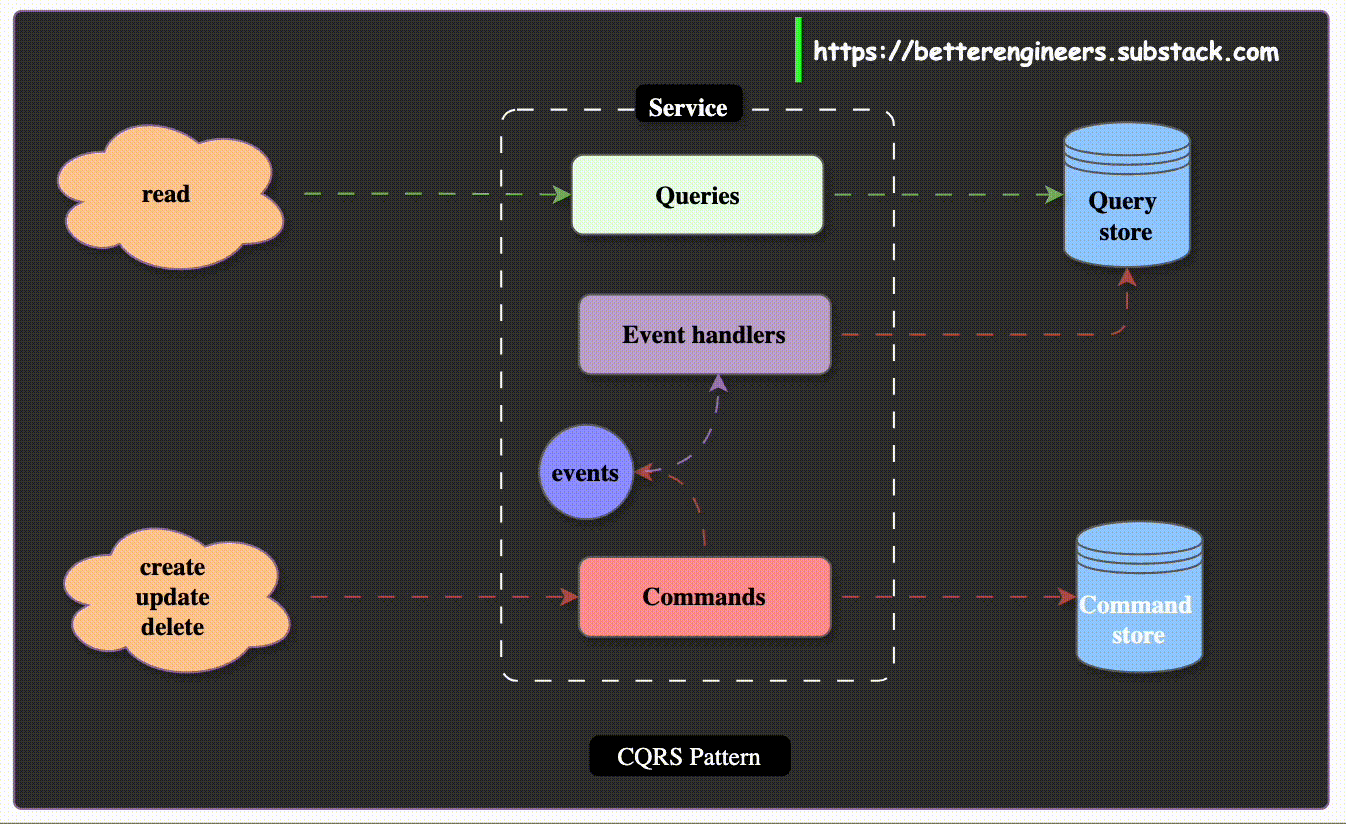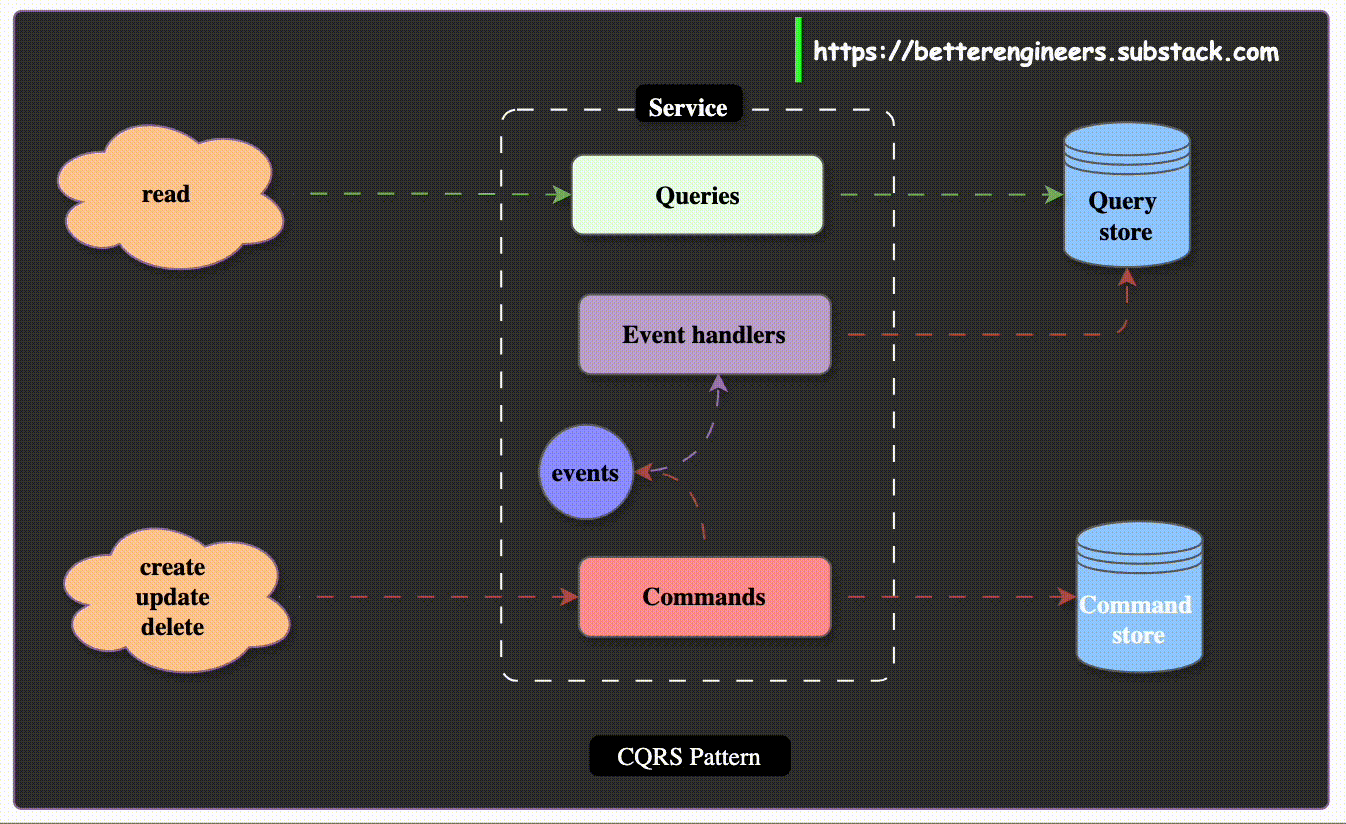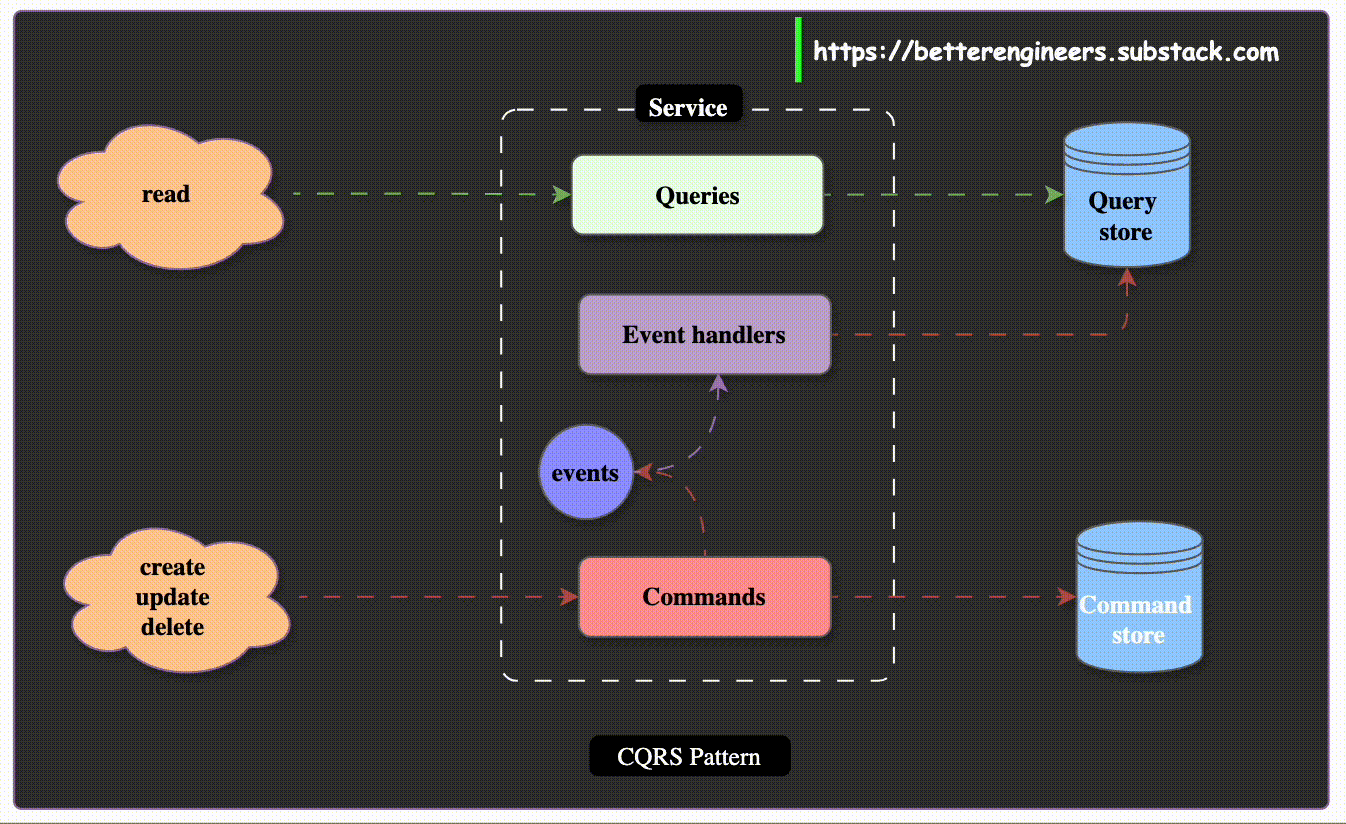
Event Handlers and Building Read Models:
Event handlers consume these events and use them to update or build read models.
Read models are designed for fast data retrieval, allowing queries to access the information they need without complex joins or aggregations at runtime.
Events provide a way to synchronize data between the command and query sides, ensuring that the read model remains up-to-date with the latest changes.
Query Side:
The query side handles retrieving data for read operations. Since queries often need to access a range of sources and provide a holistic view, they may use a separate data store that is optimized for read performance.
For example, while the command side may use a relational database like PostgreSQL for data consistency and transactions, the query side might use Elasticsearch for faster search capabilities and data aggregation.
Applying CQRS in a Microservices Environment
CQRS can be implemented within individual services or applied across the entire application. It is especially useful for building dedicated query services that aggregate data from multiple sources to construct complex views.
For instance:
Suppose you need to generate reports that aggregate order fees across all customers and slice them by attributes like order type, asset categories, or payment method. This query cannot be executed directly within the Orders, Fees, or Customers services, because each service holds only a portion of the required data.
Instead, you can use a query service called CustomerOrders to subscribe to events like OrderCreated or FeeUpdated. This service maintains a local view of all the necessary data to produce the report.
The CustomerOrders service is then responsible for handling read requests that require this aggregated view, ensuring a separation of concerns between the services that manage the underlying data and those that aggregate and present it.
Benefits of Using CQRS
Performance Optimization: By separating the read and write models, each side can be independently optimized for performance. The command side can focus on data consistency, while the query side is tailored for fast retrieval.
Scalability: The read side and write side can be scaled independently. If the application is read-heavy, you can scale the query services without affecting the command side.
Simplified Complexity: CQRS reduces the complexity of managing business logic, as each side only handles its specific responsibilities. This makes the system easier to maintain and extend.
Data Store Flexibility: Since the read and write sides can use different databases, you can select a data store that fits each side's needs best. For example, using a relational database for transactions and a NoSQL database for faster reads.
Keep reading with a 7-day free trial
Subscribe to Better Engineers to keep reading this post and get 7 days of free access to the full post archives.