A Crash Course to API

🚀 Introduction to API Development: Essential Tools and Technologies
API development has become a critical aspect of modern software architecture, enabling different applications and services to interact seamlessly 🌐. Whether you're building a simple REST API for a mobile app 📱 or a complex microservices ecosystem 🖧, selecting the right tools and technologies can significantly streamline the development process and enhance performance ⚙️. In this blog, we will explore the essential tools, frameworks, and best practices needed to create scalable, secure, and efficient APIs. From backend languages and libraries 📚 to testing tools 🧪 and deployment strategies 🚢, this guide covers everything you need to get started with robust API development.
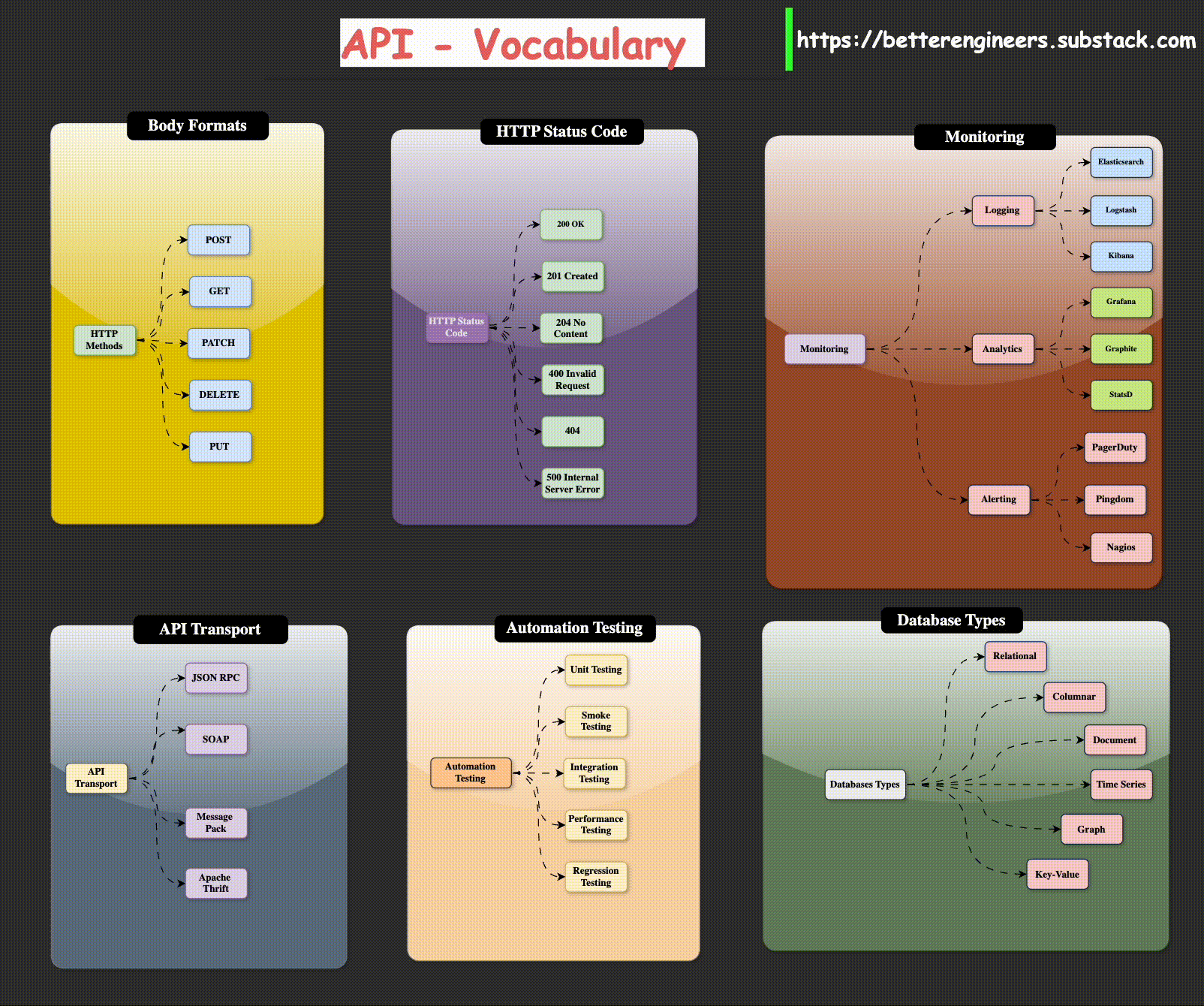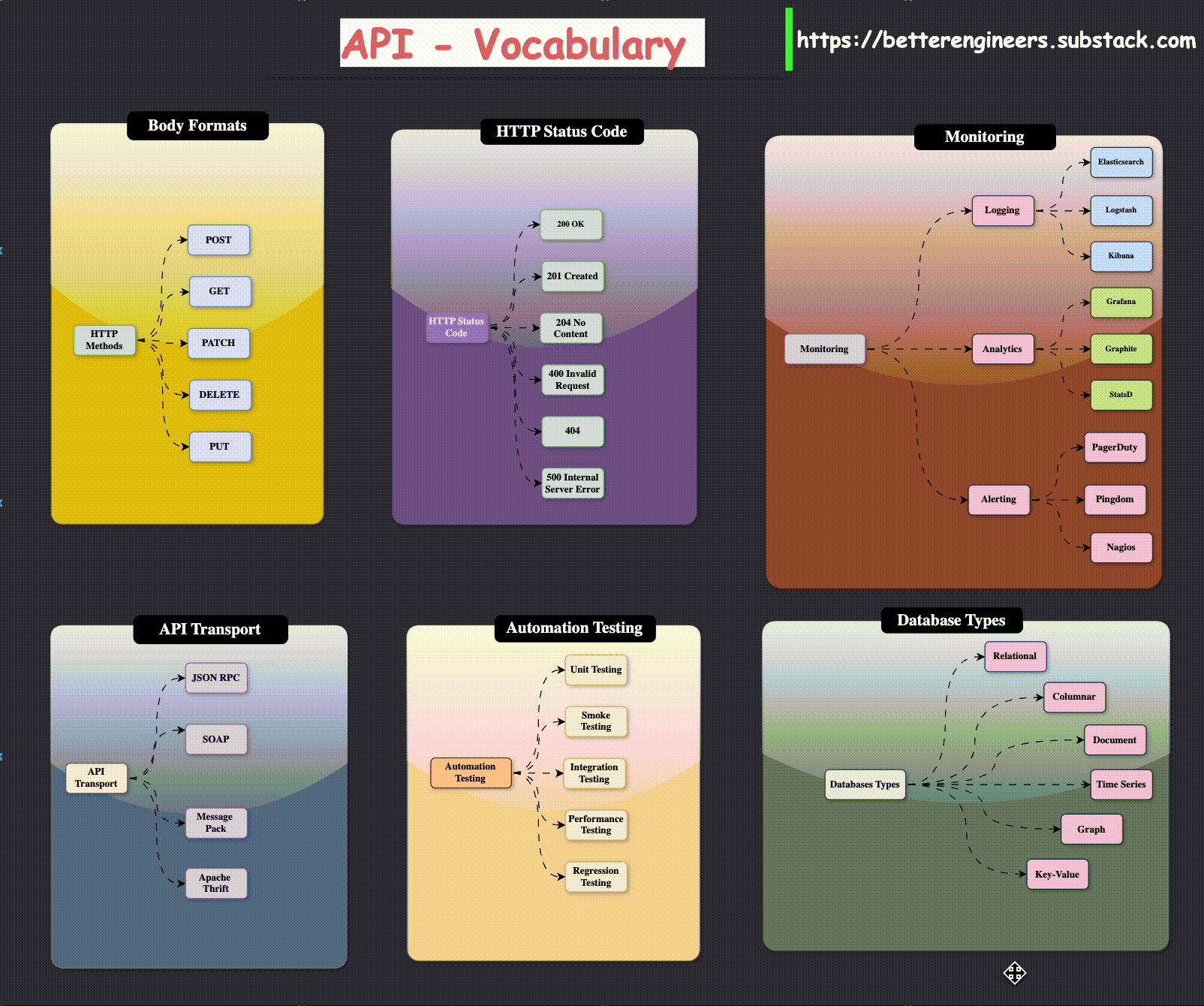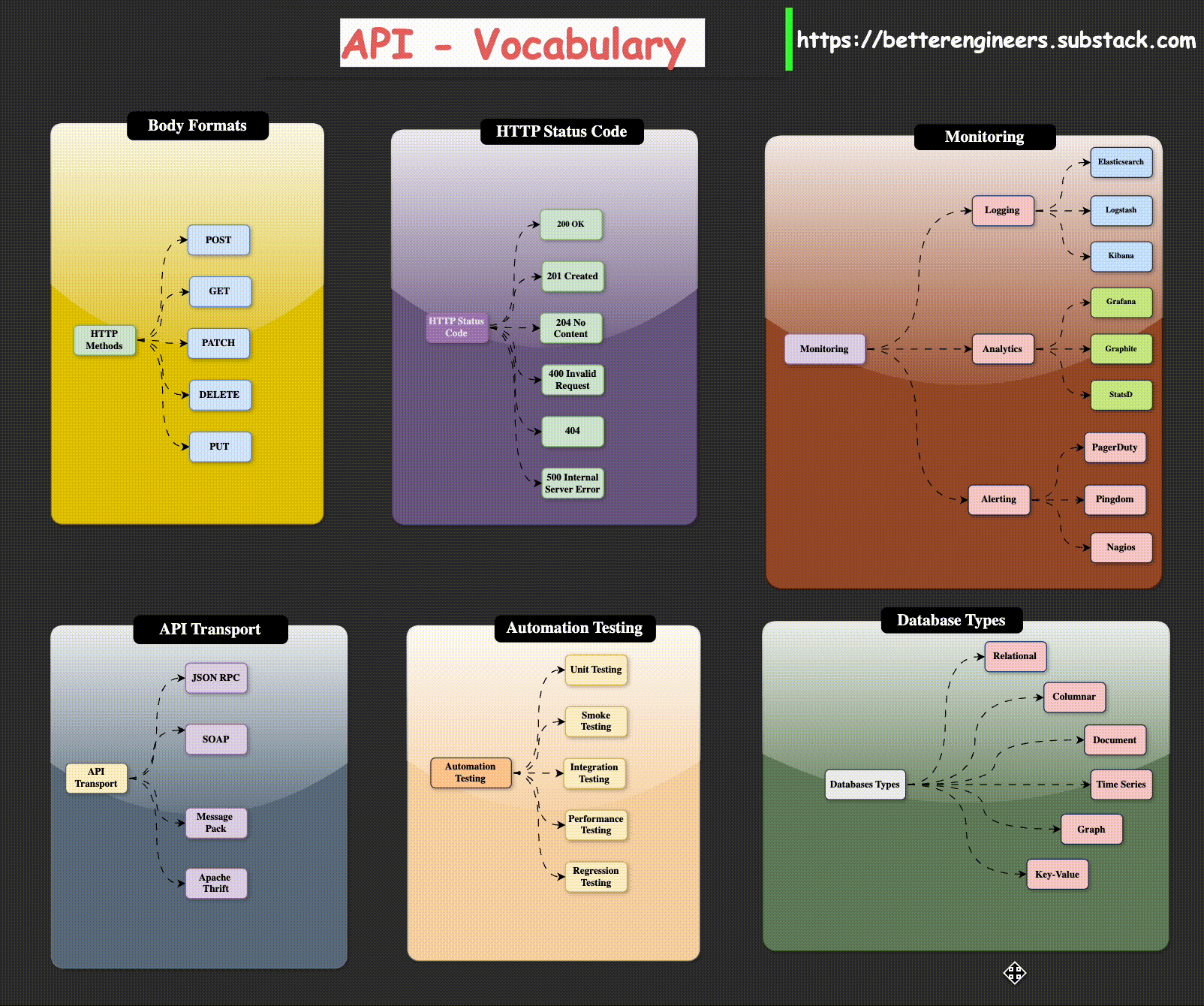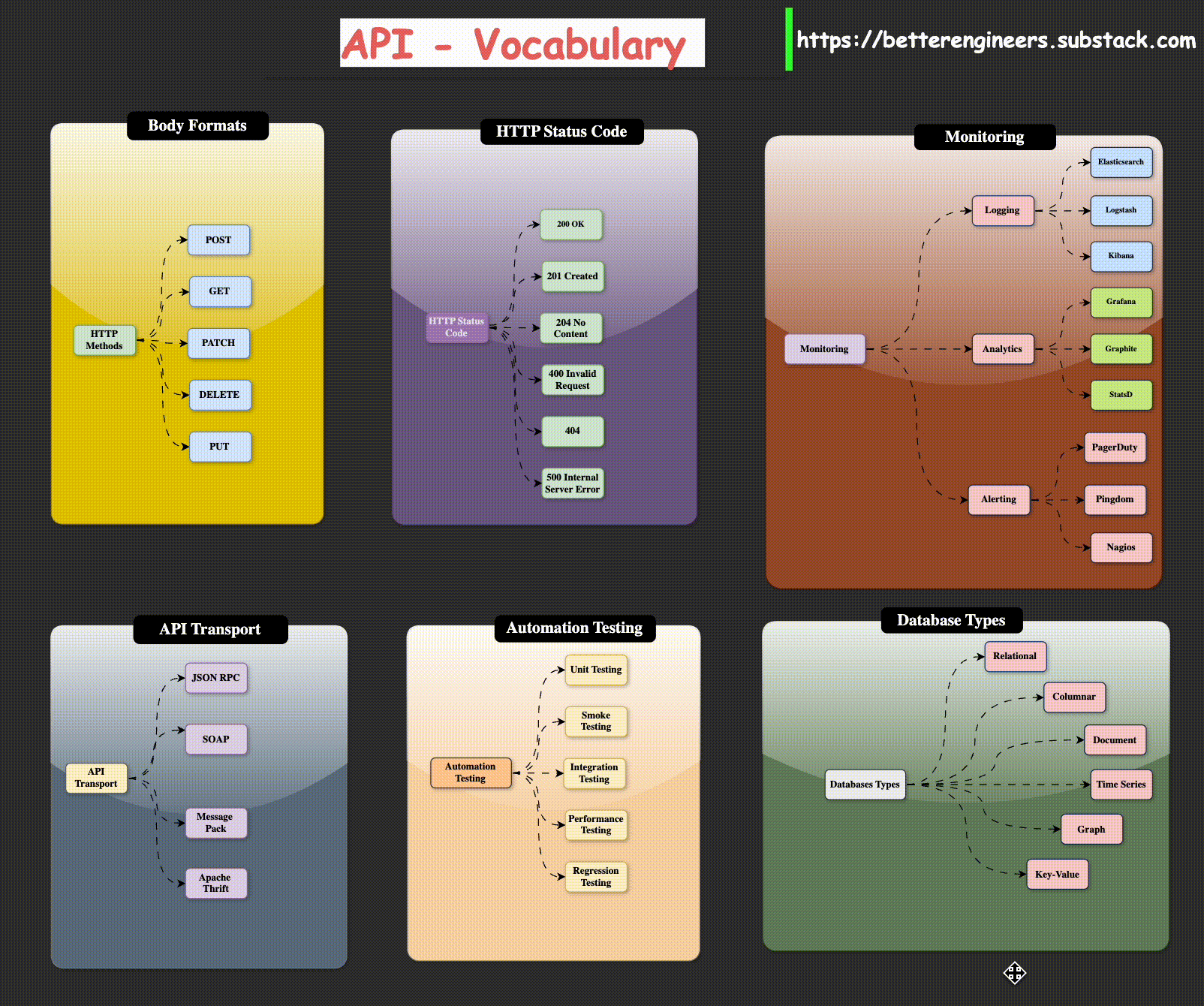
Body Formats
JSON
The JSON document used for the request should be similar to the JSON document used for the response, such as the one in below example. JSON can specify the type of data (e.g., integers, strings, Booleans) while also allowing for hierarchal relationships of data. String data needs to be escaped (e.g., a quote, “, becomes prefixed with a backslash, \”), but this is usually done automatically by a serializer.
JSON Request Body Format
POST /v1/animal HTTP/1.1
Host: api.example.org
Accept: application/json
Content-Type: application/json
Content-Length: 24
{
"name": "Gir",
"animal_type": "12"
}Form URL Encoded
The method shown in below example is used by web sites for accepting simple data forms from a web browser. Data needs to be URL encoded if it contains any special characters (e.g., a space character becomes %20). This is automatically taken care of by the browser.
Form URL Encoded Request Body Format
POST /login HTTP/1.1
Host: example.com
Content-Length: 31
Accept: text/html
Content-Type: application/x-www-form-urlencoded
username=root&password=Zion0101Multipart Form Data
The method shown in below example is used by web sites for accepting more complex data from a web browser such as file uploads. No escaping needs to happen. The boundary is a random string and shouldn’t be contained within the uploaded file or form data.
POST /file_upload HTTP/1.1
Host: example.com
Content-Length: 275
Accept: text/html
Content-Type: multipart/form-data; boundary=----RANDOM_jDMUxq
------RANDOM_jDMUxq
Content-Disposition: form-data; name="file"; filename="h.txt"
Content-Type: application/octet-stream
Hello World
------RANDOM_jDMUxq
Content-Disposition: form-data; name="some_checkbox"
on
------RANDOM_jDMUxq--HTTP Headers
The first half of the Robustness Principle is to “be liberal in what you accept from others”.According to RFC 2617’s Message Headers section, header names are case insensitive.
This means you should accept headers from consumers regardless of what the casing is.A common approach is to iterate over each header, convert it to a consistent case (for example, all lowercase), and then refer to the headers in your application using the same case.
Here are some common headers you can expect your consumers to provide:
• Accept: A list of content types the client accepts
• Accept-Language: The language the client is expecting
• Content-Length: The length of the body in bytes
• Content-Type: The type of data if a body is present
• Host: Used for virtual hosting, usually ignored by application
Headers can be a point of contention for consumers. Whenever possible, try to make them optional or try to allow their options to also be set as query parameters.For example, if your application supports multiple languages and you use the Accept-Language header to select a language, also make use of a &language= parameter. If both are provided, prefer the query parameter because it is typically more intentional (think of someone trying to override their default browser language by changing the URL).
HTTP Methods
You probably already know about GET and POST requests. These are the two most commonly used requests when a web browser accesses web pages and interacts with data. There are, however, four and a half HTTP methods that you need to know about when building an HTTP API. I say “and a half” because the PATCH method is similar to the PUT method and the functionality of the two is often combined by many APIs into just PUT.
You’ve likely heard of the phrase CRUD when referring to the seemingly boilerplate code many web developers need to write when interacting with a database. Some web frameworks will even generate CRUD scaffolding for the developer as a result of running a terminal command. CRUD stands for create, read, update, and delete, and it can be used for handling all data entry.
Here is a list of HTTP methods as well as which CRUD operation they represent. The correlated SQL command is also provided, assuming your service was to represent an extremely simple database.
POST (create)
Creates a new resource on the server
Corresponds to a SQL INSERT command
Not considered idempotent because multiple requests
will create duplicate resources
GET (read)
Retrieves a specific resource from the server
Retrieves a collection of resources from the server
Considered safe, meaning this request should not alter the server state
Considered idempotent, meaning duplicate subsequent
requests should be free from side effects
Corresponds to a SQL SELECT command
PUT (update)
Updates a resource on the server
Provides the entire resource
Considered idempotent, meaning duplicate subsequent requests should be free from side effects
Corresponds to a SQL UPDATE command, providing null values for missing columns
PATCH (update)
Updates a resource on the server
Provides only changed attributes
Corresponds to a SQL UPDATE command, specifying only columns being updated
DELETE (delete)
Destroys a resource on the server
Considered idempotent, meaning duplicate subsequent requests should be from side effects
Corresponds to a SQL DELETE command
Here are two lesser-known HTTP methods. While it isn’t always necessary that they be implemented in your API, in some situations (such as APIs accessed via web browser from a different domain) their inclusion is mandatory.
HEAD
Retrieves metadata about a resource (just the headers)
Example: a hash of the data or when it was last updated
Considered safe, meaning this request should not alter the server state
Considered idempotent, meaning duplicate subsequent requests should be free from side effects
OPTIONS
Retrieves information about what the consumer can do with the resource
Modern browsers precede all cross-origin resource-sharing requests with an OPTIONS request
Common API Status Codes
There are a plethora of HTTP status codes to choose from [10], almost to the point
of being overwhelming. The following list contains the most common status codes,
particularly in the context of API design:

200 OK
Successful GET/PUT/PATCH requests.
The consumer requested data from the server, and the server found it for the consumer.
The consumer gave the server data, and the server accepted it.
201 Created
Successful POST requests.
The consumer gave the server data, and the server accepted it.
204 No Content
Successful DELETE requests.
The consumer asked the server to delete a resource, and the server deleted it.
400 Invalid Request
Erroneous POST/PUT/PATCH requests.
The consumer gave bad data to the server, and the server did nothing with it.
404 Not Found
All requests.
The consumer referenced a nonexistent resource or collection.
500 Internal Server Error
All requests.
The server encountered an error, and the consumer does not know whether the request succeeded.
Status Code Ranges
The first digit of the status code is the most significant and provides a generalization of what the entire code is for.
1XX: Informational
The 1XX range is reserved for low-level HTTP happenings, and you’ll likely go your entire career without manually sending one of these status codes. An example of this range is when upgrading a connection from HTTP to WebSockets.
2XX: Successful
The 2XX range is reserved for successful responses. Ensure your service sends as many of these to the consumer as possible.
3XX: Redirection
The 3XX range is reserved for traffic redirection, triggering subsequent requests. Most APIs do not use these status codes; however, Hypermedia-style APIs may make more use of them.
4XX: Client Error
The 4XX range is reserved for responding to errors made by the consumer such as when the consumer provides bad data or asks for something that doesn’t exist. These requests should be idempotent and not change the state of the server.
5XX: Server Error
The 5XX range is reserved as a response when a service makes a mistake. Oftentimes these errors are created by low-level functions even outside of the developer’s control to ensure a consumer gets some sort of response. The consumer can’t possibly know the state of the server when a 5XX response is received (e.g., did a failure happen before or after persisting the change?), so these situations should be avoided.
Top-Level Collections
Pretend that you’re building a fictional API to represent several different zoos. Each contains many animals (with an animal belonging to exactly one zoo) as well as employees (who can work at multiple zoos). You also want to keep track of the species of each animal.
Given this data and these relationships, you might have the following endpoints:
https://api.example.com/v1/zoos
https://api.example.com/v1/animals
Specific Endpoints
While conveying what each endpoint does, you’ll want to list valid HTTP methods and endpoint combinations. For example, here’s a list of actions that you can perform with your fictional zoo-keeping API. Notice you precede each endpoint with the HTTP method. This is a common notation and is similar to the one used within an HTTP request status line.
GET /v1/zoos: List all zoos (perhaps just ID and name)
POST /v1/zoos: Create a new zoo
GET /v1/zoos/{zoo_id}: Get entire zoo resource
PUT /v1/zoos/{zoo_id}: Update zoo (entire resource)
PATCH /v1/zoos/{zoo_id}: Update zoo (partial resource)
DELETE /v1/zoos/{zoo_id}: Delete zoo
GET /v1/zoos/{zoo_id}/animals: List animals (ID and name) at this zoo
GET /v1/animals: List all animals (ID and name)
POST /v1/animals: Create new animal
GET /v1/animals/{animal_id}: Get animal
PUT /v1/animals/{animal_id}: Update animal (entire resource)
PATCH /v1/animals/{animal_id}: Update animal (partial resource)
GET /v1/animal_types: List all animal types (ID and name)
GET /v1/animal_types/{animaltype_id}: Get entire animal type resource
GET /v1/employees: List all employees
GET /v1/employees/{employee_id}: Get specific employee
GET /v1/zoos/{zoo_id}/employees: List employees at this zoo
POST /v1/employees: Create new employee
POST /v1/zoos/{zoo_id}/employees: Hire an employee for zoo
DELETE /v1/zoos/{zoo_id}/employees/{employee_id}: Fire employee from zoo.
Error Reporting
Errors are an inevitability of any cross-service communication. Users will fat finger an e-mail address, developers will not read the tiny disclaimer you hid in your API documentation, and a database server will occasionally burst into flames. When this happens, the server will of course return a 4XX or 5XX HTTP status code, but the document body itself should have useful information included.
Validation Errors
When an error happens regarding a malformed attribute, provide the consumer with a reference to the attribute causing the error as well as a message about what is wrong, as in below example. Assuming the consumer is providing a user interface (UI) for a user to input data, the UI can display the message for the user to read as well as provide context for the user.
Request
PUT /v1/users/1
{
"name": "Rupert Styx",
"age": "Twenty Eight"
}Response
HTTP/1.1 400 Bad Request
{
"error_human": "Inputs not formatted as expected",
"error_code": "invalid_attributes",
"fields": [
{
"field": "age",
"error_human":"Age must be a number between 1 and 100",
"error_code": "integer_validation"
}
]
}Generic Errors
When an error occurs that can’t be traced back to a single input attribute being incorrect,you’ll want to return a more generic error construct.
Request
POST /v1/animals
{
"name": "Mittens",
"type": "kitten"
}
Response
HTTP/1.1 503 Service Unavailable
{
"error_human": "The Database is currently unavailable.",
"error_code": "database_unavailable"
}API Standards
So far, all the example response bodies have been simple representations of resources or arrays of resources. There is important meta-information that you could be providing as well as intrinsic methods for describing the purpose of data.
JSON Schema
JSON Schema provides a method for describing the attributes provided by an API endpoint. This description is written in JSON in such a way as to be both human-readable and easy to work with programmatically. Using JSON Schema, a consumer could easily automate data validation and generation of CRUD forms.
GraphQL
GraphQL is an API specification created by Facebook. It requires the use of a unique query language as well as a similar language for defining schemas. The data returned is typically formatted as JSON though it doesn’t enforce a format. GraphQL makes use of a single HTTP endpoint.
What really makes GraphQL unique is the way it allows you to define relationships between resources and then receive multiple resources using a single query, a feature that a purely RESTful approach can’t account for.
Hypermedia APIs
It would be irresponsible to cover HTTP-based API design without mentioning Hypermedia/Representational State Transfer (REST). Hypermedia APIs may very well be the future of HTTP API design. It really is an amazing concept going back to the roots of how HTTP (and HTML) was intended to work.
JSON Attribute Conventions
JSON is a subset of JavaScript and was defined for the purpose of building a languageagnostic data interchange format. It fills mostly the same role that XML was designed to fill except that it has the side effect of being much more compact and easily deserializes into native objects in most languages. It also supports many different data types, whereas XML technically only supports strings without the inclusion of metadata.
Snake Case
Snake case, uses lowercase words with underscores to separate them. This format uses the most bytes and seems to be the most common approach used in RESTful JSON APIs. For example, GitHub and Stripe follow this approach.
{
"id": "alice",
"first_name": "Alice"
}Pascal Case
Pascal case, uses a capital letter for all words. This format seems to be most common in the Microsoft .NET/enterprise world.
{
"Id": "alice",
"FirstName": "Alice"
}Camel Case
Camel case, uses a capital letter for all words except for the first one. This minimizes the number of times a developer has to press Shift.
{
"id": "alice",
"firstName": "Alice"
}If you find this article useful Please leave a like , subscribe and share my blog .
Follow me on LinkedIn | X
Cheat Sheet for API Design Tools and Technologies