


Apache Kafka Producer — Implementation
Kafka serves as a robust foundation for real-time data processing, offering a distributed streaming platform that excels in constructing dynamic data pipelines and streaming applications.

Learn Apache Kafka From Basics
In this series, I will explain the benefits of Apache Kafka from the basics and how to integrate it into the client.
In this part, I will teach you how to use Apache Kafka even if you are a beginner and don’t have any prior knowledge of Apache Kafka.
Let’s take a use case where we can use Apache Kafka and How we can use it.
Problem: Suppose we have a Client Application that collects Analytics from your App and sends it to the Server with a regular Interval.
As this data is very important, we should not lose any data when sending it to the analytics server and It can consume all the requests coming from different servers.
Answer: One thing we can understand is we need a Reliable and Scalable system as we can not afford to lose any data and our system can consume hundreds of requests.
Let’s Implement without Apache Kafka :

Sample code to send data to the server by using HttpURLConnection in Java :
public void sendLog(String url, Request request){
URL serverUrl = new URL(url);
HttpURLConnection conn = (HttpURLConnection) serverUrl.openConnection();
conn.setRequestMethod("POST");
conn.setDoOutput(true);
conn.setRequestProperty("Content-Type", "application/json");
String jsonPayload = request.toString();
System.out.println("Response from server:" + jsonPayload);
DataOutputStream outputStream = new DataOutputStream(conn.getOutputStream());
outputStream.writeBytes(jsonPayload);
outputStream.flush();
outputStream.close();
}Everything looks good so far but when we talk about Reliability we can not trust HTTP Connection as it’s Stateless and when Hundreds of clients will send thousands of requests our Server will not be able to handle them until we do Scaling.
What if we have multiple sources to send different types of Logs, how do we handle these different logs server-side e.g
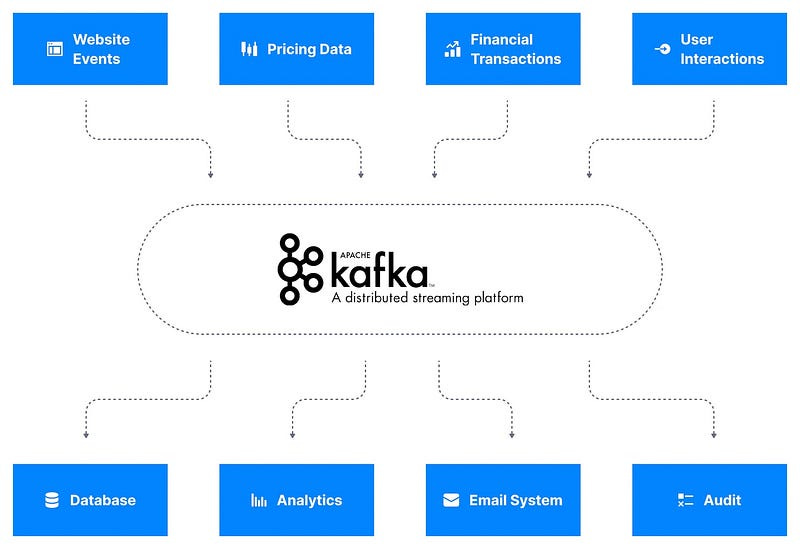
Let’s fix this problem with Apache Kafka :
Data Sources will publish their data to Apache Kafka, After that Kafka will distribute the data stream to the desired destination, but how?

Here topic will help us,
Kafka topics organize related events. For example, we may have a topic called logs, which contains logs from an application. Topics are roughly analogous to SQL tables. However, unlike SQL tables, Kafka topics are not queryable. Instead, we must create Kafka producers and consumers to utilize the data. The data in the topics are stored in the key-value form in binary format.
In our case, I have created a Topic Analytics in our code but we can have multiple topics like Purchase for storing Purchasing records, Email, etc

As you can see in the Diagram Client will create a Producer that will send Data to Apache Kafka, Kafka will assign this data based on the Topic and send it to the Server where we will have a consumer that will consume data based on the Topic.
Let’s setup Kafka Producer in Eclipse :
We only need few dependencies to add in pom.xml
<dependencies>
<!-- Add your dependencies here -->
<dependency>
<groupId>ch.qos.logback</groupId>
<artifactId>logback-classic</artifactId>
<version>1.2.6</version> <!-- Use the latest version -->
</dependency>
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>3.1.0</version> <!-- Use the version you need -->
<exclusions>
<exclusion>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-api</artifactId>
<version>1.7.32</version> <!-- Use the version you need -->
</dependency>
<dependency>
<groupId>log4j</groupId>
<artifactId>log4j</artifactId>
<version>1.2.17</version> <!-- Use the version you need -->
</dependency>
<!-- Add more dependencies here -->
</dependencies>After Adding dependencies in our code we can be good to go.
Kafka Configuration :
public interface KafkaConfiguration {
String TOPIC_NAME = "analytics";
String SERVER_URL = "localhost:9092";
String KEY = "org.apache.kafka.common.serialization.StringSerializer";
String VALUE = "org.apache.kafka.common.serialization.StringSerializer";
}Create Kafka Properties:
Properties props = new Properties();
props.put("bootstrap.servers", SERVER_URL);
props.put("key.serializer", KEY);
props.put("value.serializer", VALUE);Create Producer and Send Data :
private void sendMessage(Request request) {
KafkaProducer<String, String> producer = new KafkaProducer<String, String>(props.getProperties());
ProducerRecord<String, String> pr = new ProducerRecord<>(KafkaConfiguration.TOPIC_NAME, "key", request.toString());
producer.send(pr, (metadata, exception) -> {
if (exception != null) {
System.err.println("Error sending message: " + exception.getMessage());
} else {
System.out.println("Message sent successfully: topic=" + metadata.topic() + ", partition="
+ metadata.partition() + ", offset=" + metadata.offset());
}
});
producer.close();
}This is how we will create a Producer and send data to Kafka Consumer, in the next post I will let you know how to set up Kafka, nodejs, MongoDB, create a Topic, receive data from the consumer, and save this data to Database .
Source code for
Please follow and like for more awesome tutorials.
Can you share any resources to learn more about the kafka